목차
출처


1. Bagging(Bootstrap Aggregation)
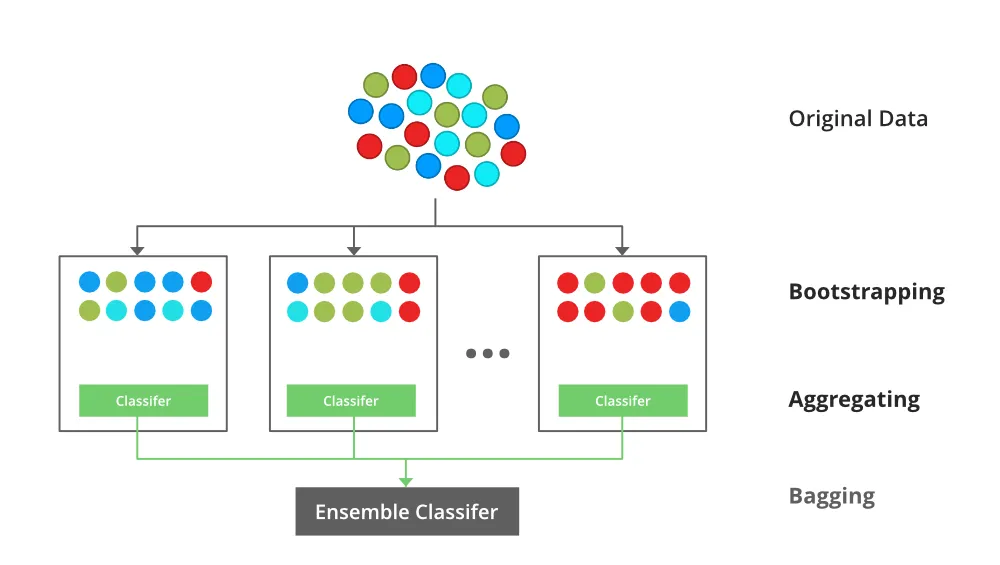
전체 데이터를 랜덤하게 여러 번 추출해 샘플을 만들고(Bootstrap), 각각의 데이터를 사용해 병렬적(parallel)으로 학습한 모델의 예측값을 집계(Aggregation)하는 방식을 의미한다. 중복을 허용하기 때문에 각각 bootstrap sample에는 동일한 데이터가 포함될 수 있다. 집계할 때는 별도의 가중치 없이 동일한 비중으로 모델 결과를 취합한다.
Bagging을 시험 문제 풀이에 비교하자면 한 학생의 답안만을 참고하는 대신에 여러 학생의 답안 결과를 평균을 내거나(Regression) 더 많은 표를 받은(Classification) 답을 참고하는 셈이다.

Boosting 대비 robust & 속도 빠름
편향이 아닌 분산 감소가 목표
복잡한 문제일 경우 Boosting 대비 성능 낮음
2. Boosting
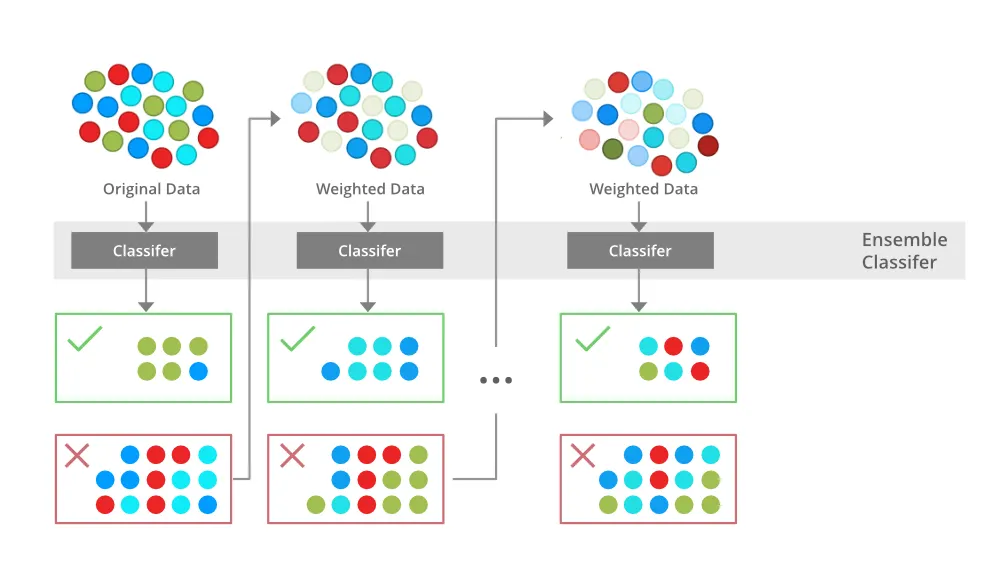
이전 모델의 오류를 반영해 오분류된 데이터에 가중치를 주고 다음 모델을 만들어 나가는 방식으로 순차적(sequential)으로 학습한 모델의 예측값을 집계한다. Bootstrap sample을 생성해 학습하는 것은 Bagging과 동일하지만 학습을 진행할 때마다 데이터의 가중치를 달리 하기 때문에 분포가 달라진다. 또한 최종 결과를 취합할 때에도 각 모델에 가중치를 주어 취합한다.
Boosting을 시험 문제 풀이에 비교하자면 학생 1의 오답을 분석해 학생 2로 하여금 오답 유형의 연습문제를 풀게 한 뒤에 시험을 보는 것과 같다. 학생 3은 학생 2의 오답 유형에 대비하기 때문에 오답률을 낮추는 방향으로 문제를 풀게 되는 셈이다.
Bagging 대비 성능 높음
분산이 아닌 편향 감소가 목표
Bagging 대비 과적합 위험 높음
3. Stacking
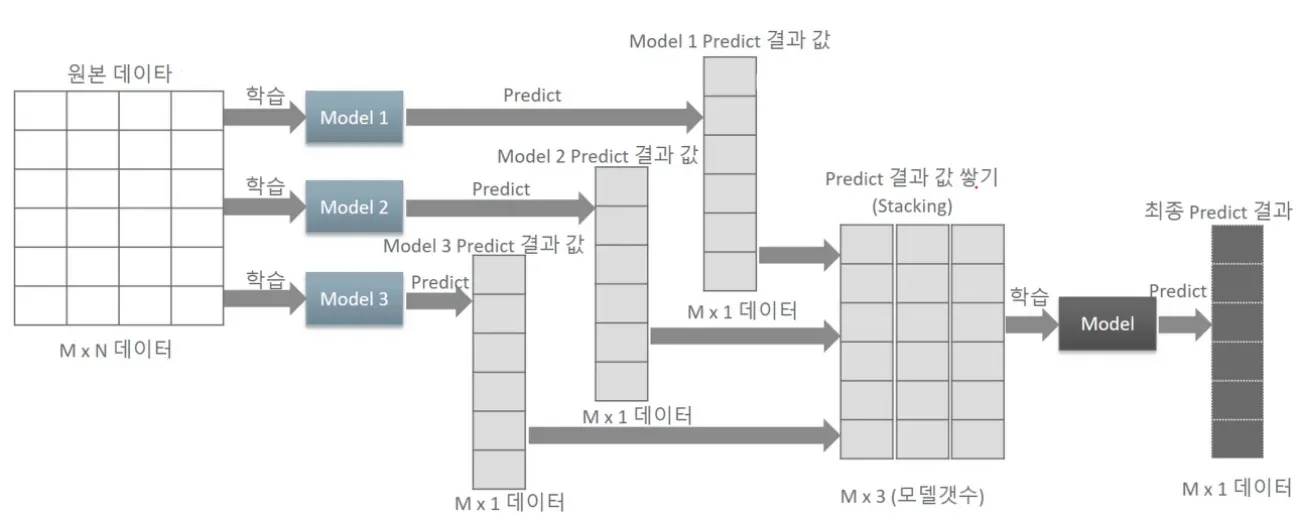
Bagging과 마찬가지로 병렬적(parallel)으로 학습하지만 동일한 데이터셋을 사용하며 각각의 모델은 서로 다른 알고리즘을 학습해 예측을 수행한다. 각각의 예측값이 새로운 feature가 되도록 그대로 쌓아 최종 데이터셋을 생성하고 사전에 설정해두었던 메타 모델을 학습해 최종 예측값을 얻는다.
성능 개선을 보장할 수 없으며 과적합 위험이 있기 때문에 일반적으로 교차검증(CV) 기반으로 예측한 데이터를 활용해 최종 데이터셋을 생성한다.
cf.) CV 기반 Stacking
다양한 알고리즘을 사용할 수 있음
분산이 아닌 편향 감소가 목표
Bagging, Boosting 대비 과적합 위험 높음