
출처


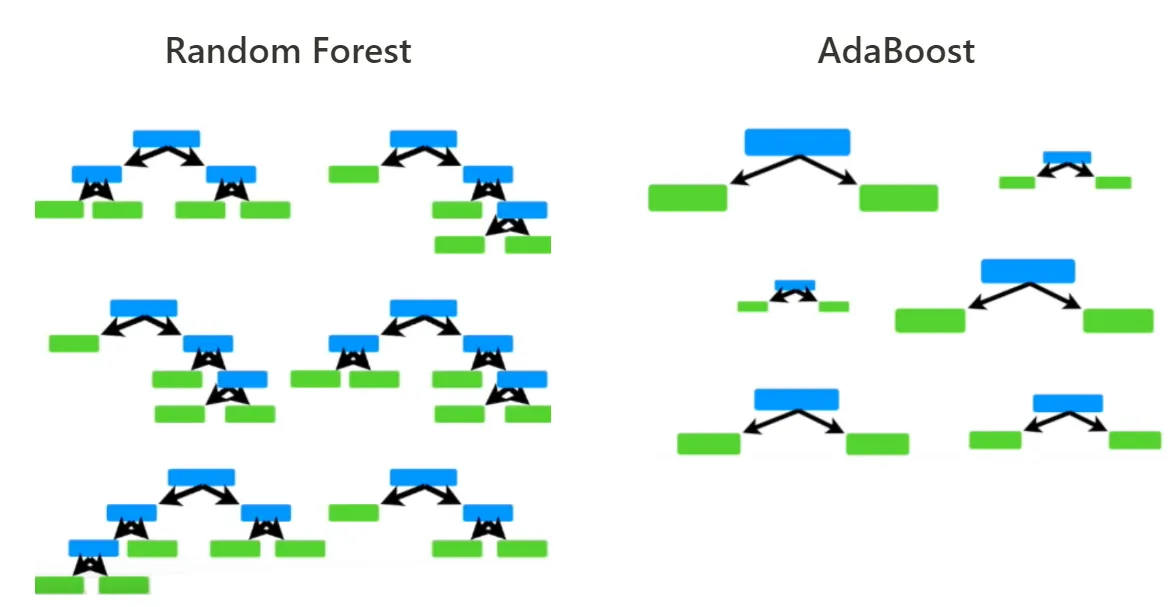
Boosting 알고리즘을 Decision Tree에 그대로 적용한 모델이다. 1번째 모델에서 오분류된 데이터는 2번째 모델에서 더 큰 가중치를 갖는다. 즉, 매 학습마다 데이터의 분포가 달라지기 때문에 모델 간의 correlation을 낮추며, 이는 Random Forest와 유사한 역할을 한다고 볼 수 있다.
하지만 여러 개의 Tree를 생성하는 Random Forest와 달리 AdaBoost는 노드 하나와 leaf 2개로 이루어진 트리인 stump를 여러 개 생성한다. 또한 각 tree에 동일한 가중치를 주는 Random Forest와 달리 AdaBoost는 각 stump에 sequential한 가중치를 준다.
•
알고리즘
