
출처



AdaBoost와 달리 stump가 아닌 하나의 leaf에서 시작하며, 그 이후에는 이전 tree의 pseudo-residual을 반영한 새로운 tree를 생성하는 과정을 반복한다. 각 pseudo-residual은 이전 모델들의 예측값과 실제값의 차이로 정의한다. 이 때 과적합을 피하기 위해 각 tree에 일정 learning rate를 곱해준다(Shrinkage). 즉, learning rate는 pseudo-residual에 fitting된 모델을 어느 정도로 update할 것인지를 결정하는 hyperparameter인 셈이다.
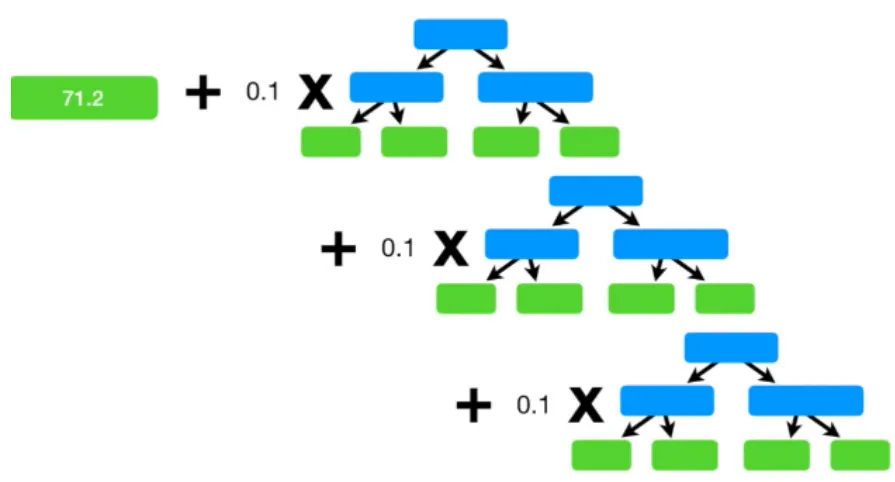
따라서 각각의 모델은 다음과 같이 이전 모델의 pseudo-residual을 예측하는 방향으로 학습을 진행하며, 이는 곧 loss function을 줄이는 방향인 negative gradient를 계산하는 것과 다름없기 때문에 Gradient Boosting Machine이라고 부른다.
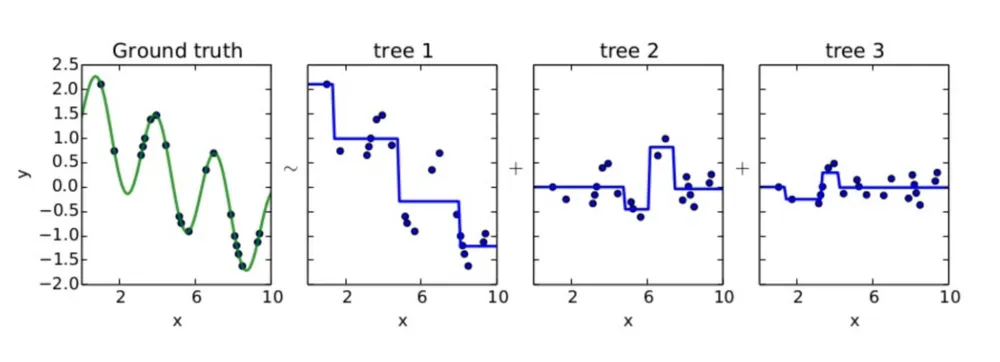
•
알고리즘

loss function은 문제에 따라 다양하게 정의할 수 있다.
