목차
출처




1. 정의
범주형 변수를 처리하는 데 초점을 맞춰 XGBoost, LightGBM 등 기존 GBM 기반 모델을 개선한 모델이다. 자체적으로 과적합을 해결하기 때문에 hyperparameter tuning 없이도 성능이 좋은 편이다.
2. 기존 GBM 기반 모델의 문제점
Boosting 특성상 과적합 위험이 큼
→ 이전 트리를 고려해 다음 트리를 생성(Prediction Shift)하기에 학습 데이터 의존성이 높아짐(Target Leakage)
Decision Tree 기반 모델 특성상 범주형 변수 인코딩 필요
→ cardinality가 높은 고차원 데이터를 원핫인코딩할 경우 너무 많은 변수가 생성됨
3. CatBoost의 해결방법
•
Level-wise 방식, Ordered Boosting → 과적합 방지
•
Ordered Target Encoding(Mean Encoding), Categorical Feauture Combinations → 범주형 변수 처리
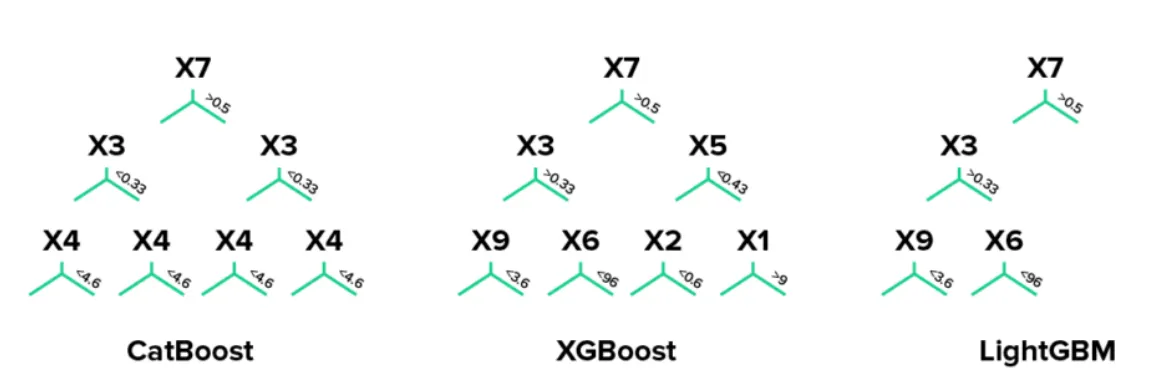
Level-wise 방식
XGBoost의 Level-wise 방식을 사용하지만 대칭적(symmetric)으로 Tree를 생성해 과적합을 최소화한다. 이처럼 동일한 레벨의 Tree에서는 동일한 cut-offf를 사용하는 ODT(Obilvious Decision Tree)로 Tree를 생성하기 때문에 메모리 효율 또한 높일 수 있다.
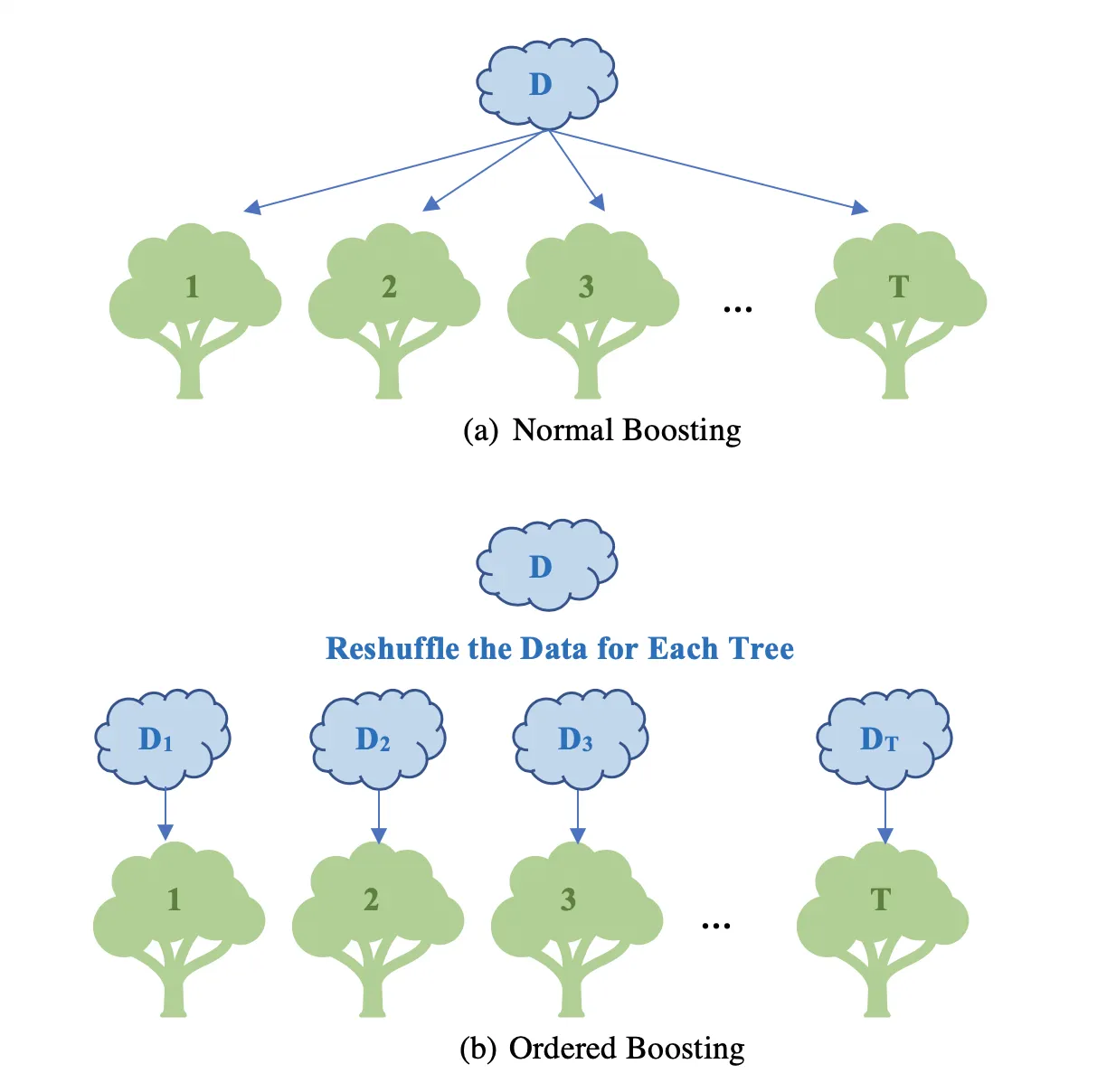
Ordered Boosting
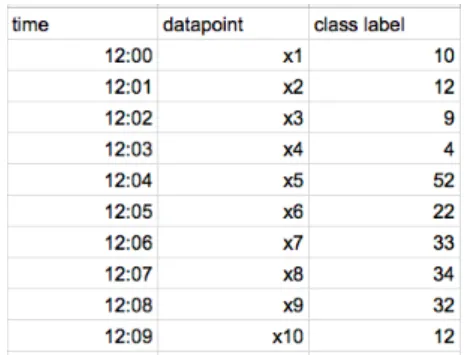
전체 데이터셋을 한 번에 사용하는 기존 GBM 기반 모델들과 달리 전체 데이터셋을 샘플링해 일부 데이터만을 사용해 Boosting을 진행한다. 이 때 데이터셋의 순서를 임의로 섞어야 한다.
1.
x1의 잔차로 모델 학습 → x2의 잔차를 예측
2.
x1, x2의 잔차로 모델 학습 → x3, x4의 잔차를 예측
3.
x1, x2, x3, x4의 잔차로 모델 학습 → x5, x6, x7, x8의 잔차를 예측
4.
1~3 반복
Ordered Target Encoding
•
cardinality가 낮은 변수 - 기존 방식대로 원핫인코딩
•
cardinality가 높은 변수 - target class가 동일한 이전 시점의 데이터의 평균으로 인코딩
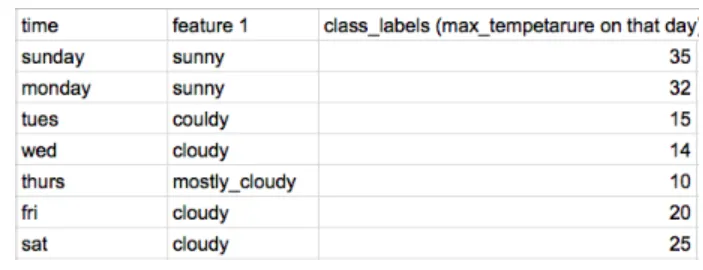
※ friday를 인코딩할 때는 saturday의 class label을 사용해서는 안됨
Categorical Feauture Combinations
Information Gain이 동일한 범주형 변수를 하나로 묶어 cardinality를 낮춤
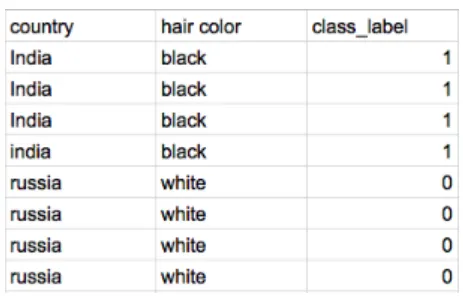
country만으로 hair color가 결정됨
4. 장단점

범주형 변수 처리에 있어 속도 빠름 & 메모리 사용량 적음
XGBoost, LightGBM 대비 tuning에 민감하지 않음
sparse한 데이터에는 취약함
범주형 변수가 없는 데이터셋에서는 성능 개선 거의 없음 & 속도 느림