목차
1. 정의
만약 모델 훈련에 모든 훈련 데이터를 한번에 사용하면 나중에 모델을 테스트할 때 성능이 좋지 않은 경우가 생긴다. 이를 과적합(overfitting)이라고 한다. 따라서 이를 피하기 위해 훈련 데이터 세트 전체를 한 번에 훈련시키지 않고, 일부를 남겨두고 테스트 하는 것에 사용하는데 이를 Cross-Validation(교차검증)이라고 한다.
2. K-Fold Cross Validation의 순서
1.
데이터를 k개의 그룹으로 랜덤하게 나눈다.
2.
한 그룹을 학습에 사용한다.
3.
다른 그룹을 사용하여 Test 및 성능을 평가한다.
4.
2,3 번의 과정을 k번 반복한다.
5.
모든 결과의 평균을 측정한다.
3. 교차 검증 반복자(Cross Validation Iterators)
교차 검증 반복자는 그룹을 나누고 성능을 테스트 하는 방식을 결정한다. 반복자의 선정은 데이터 세트의 모양과 구조에 따라 선택된다.
3-1. 데이터가 독립적이고 동일한 분포를 가지는 경우
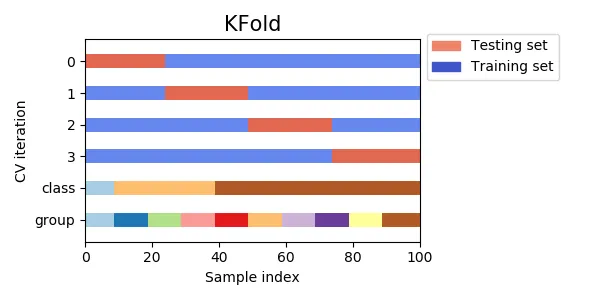
1.
KFold
•
모든 데이터를 Fold라고 불리는 그룹으로 나누고 이를 split 하여 데이터 자체에서 훈련 데이터, 테스트 데이터를 반복적으로 선정한다.
2.
RepeatedKFold
•
KFold를 n번 반복하는 반복자이다. 각 반복마다 다른 분할을 생성하여 진행한다.
3.
LeaveOneOut(LOO)
•
간단한 교차 유효성 검사를 위한 반복자이다. 하나의 데이터만을 테스트 데이터로 사용한다. 데이터가 적을 때 데이터 낭비를 막는 방식.
4.
LeavePOutLeaveOneOut(LPO)
•
LOO 반복자와 KFold를 섞은 방식의 반복자로, KFold와 아주 유사하다.
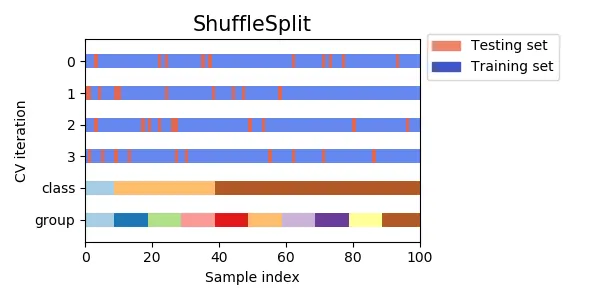
5.
ShuffleSplit
•
데이터를 먼저 섞은 후에 Fold를 분할하는 방식이다. KFold의 대안으로 좀 더 세밀한 반복자를 형성한다.
3-2. 데이터가 동일한 분포를 가지지 않는 경우
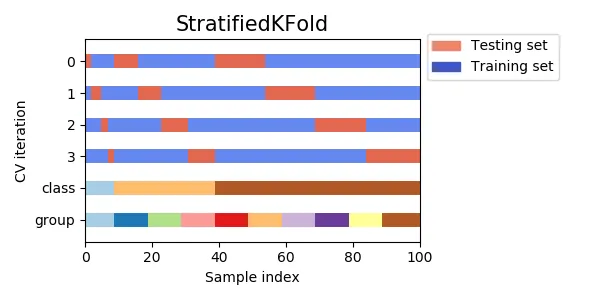
1.
StratifiedKFold
•
계층을 가진 Fold를 리턴하는 KFold의 변형된 반복자이다. 각각 비율이 다른 클래스의 비율을 유지하면서 훈련과 테스트 세트를 분류한다.
2.
RepeatedStratifiedKFold
•
StratifiedKFold 방식을 n번 반복한다.
3.
StratifiedShuffleSplit
•
계층화된 클래스의 비율을 유지하면서 Shuffle을 하는 방식이다.
3-3. 그룹화된 데이터의 경우
1.
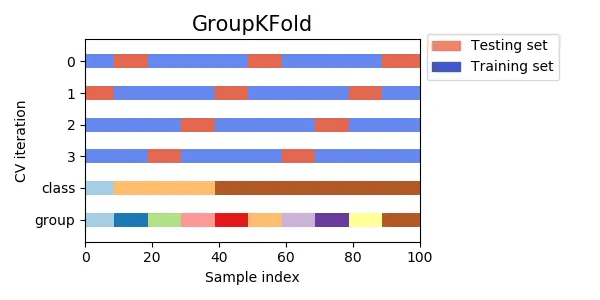
GroupKFold
•
동일한 한 클래스가 테스트 또는 훈련 데이터 세트에 한 번에 들어가지 않도록 한다. 각각 클래스들의 특징을 살리기 위한 방식이다.
2.
LeaveOneGroupOut
•
하나의 클래스를 제외시키고 GroupKFold를 하는 방식이다. 주로 시간과 관련된 데이터에서 많이 사용된다.
3.
LeavePGroupsOut
•
하나가 아닌 P개의 클래스를 제외하는 방식이다.
4.
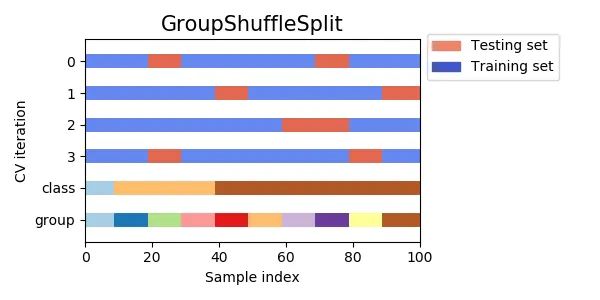
GroupShuffleSplit
•
ShuffleSplit과 GroupKFold를 합친 방식이다. 클래스의 치우침을 방지하고 랜덤 분할하는 방식이다.
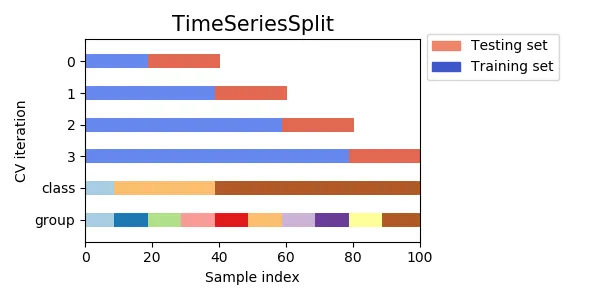
3-4. 시계열 데이터의 경우
1.
TimeSeriesSplit
•
그룹을 나누는 것은 동일하지만, 시계열 데이터는 연속적인 데이터를 유지해야 하므로, 앞에서 훈련시킨 것들을 다음에도 연속적으로 사용한다. 훈련 데이터 세트를 키워나가는 식으로 진행된다.