
출처
1. 샘플링(Sampling)
샘플링은 모집단에서 임의의 표본들을 뽑아내는 것으로 표본 추출을 의미한다.
샘플링을 하는 이유는 모집단을 전부 조사하는 것이 불가능하기 때문이다. 따라서 샘플링을 이용하여 모집단에 대한 추론을 수행한다.
추출된 표본은 가능한 모집단을 대표할 수 있는 것이 좋으며, 완벽하게 모집단과 동일하지 않기 때문에 분석시 신뢰구간, 오버피팅 등으로 고려해줄 필요가 있다.
2. 리샘플링(Resampling)
리샘플링은 말 그대로 샘플링을 다시 수행하는 것이다. 이 때 샘플링을 수행하는 대상은 원래의 샘플 즉, 표본이다. 리샘플링을 수행하는 이유는 샘플의 부분집합을 뽑아서 통계량의 변동성을 확인하기 위함이다. 주로 사용되는 방법은 k-fold 교차 검증, 부트스트랩핑(Bootstrapping)이 있다.
2-1. K-fold 교차 검증(Cross Validation)
k-fold는 샘플에서 k-1개의 동일한 크기의 부분집합들을 만들어 훈련 세트로 사용하고 나머지 하나의 부분집합을 테스트 세트(또는 검증 세트)로 사용하는 것을 말한다. 이렇게 하면 총 k개의 훈련/테스트 세트가 만들어지며 k번의 훈련과 테스트를 거쳐 k개의 테스트 결과값의 평균을 얻을 수 있다.
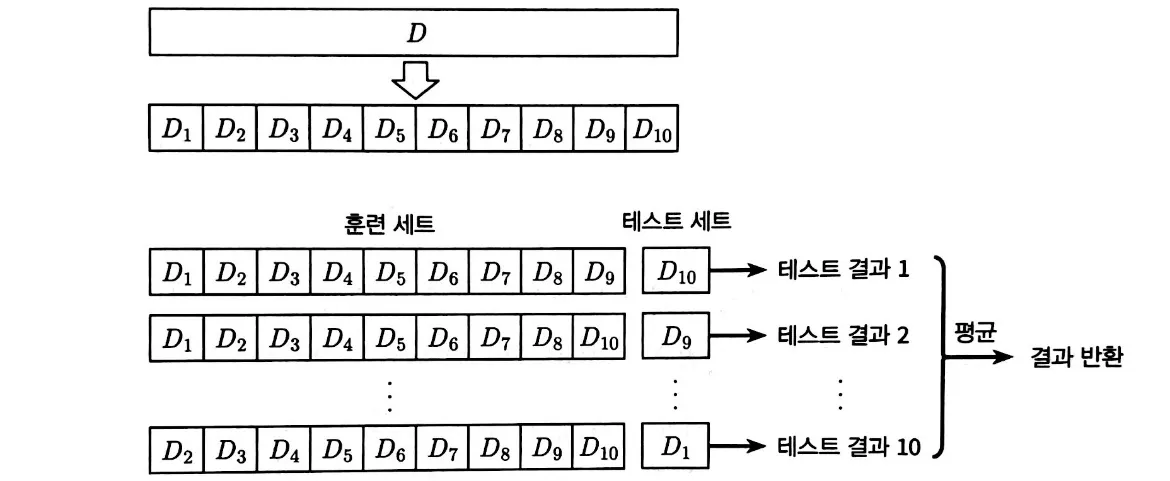
평가 결과와 안정성, 정확도는 k값에 의존하며 일반적으로 k는 10을 두고 검증한다. 데이터가 작거나 큰 경우에는 변경할 수 있다.
또한 샘플을 나누는 과정에서 bias가 발생할 수 있기 때문에 일반적으로 p번을 랜덤하게 반복하여 나누어서 진행한다. 즉, 최종적으로 p번의 k겹 교차 검증을 수행하게 된다.
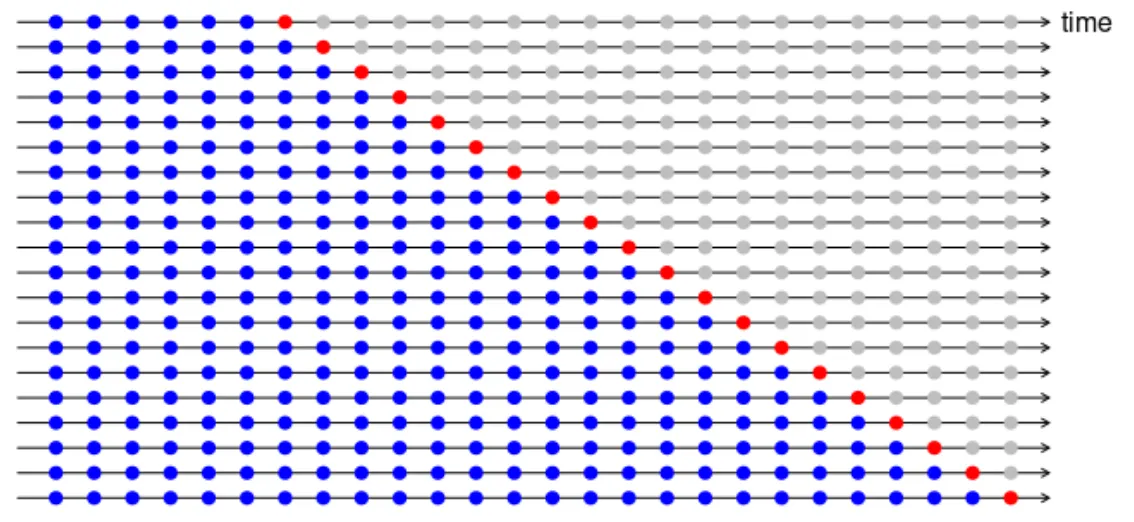
2-2. 시계열 교차 검증
시계열 데이터 분석에서 교차검증을 할 때는 시간 순서를 유지해야 한다.
1-step CV
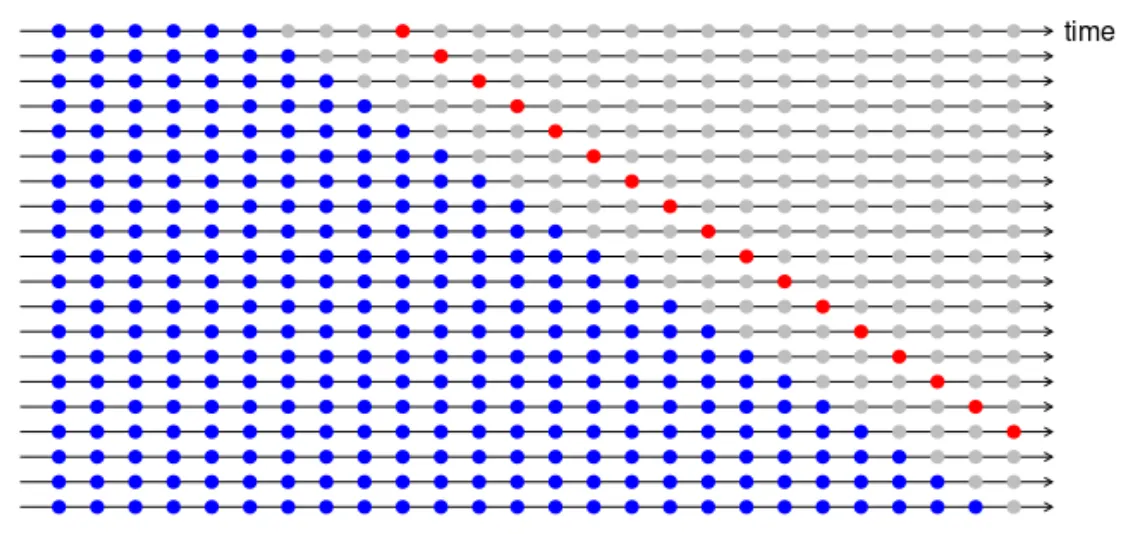
4-step CV
시계열 예측에서 특정 데이터는 바로 이후 데이터가 아닌 일정 스텝 이후의 데이터와 관련이 있는 경우가 있을 수 있기 때문에 다음과 같이 테스트 데이터를 n 스텝 이후의 값으로 지정하고 교차검증을 수행할 수도 있다
2-3. 부트스트래핑(Bootstrapping)
원래 부트스트래핑(bootstrapping) 방식은 다음과 같다.
1.
n개의 표본에서 m개를 복원 추출한다.
2.
m 번 재표본추출한 값의 평균을 구한다.
3.
1-2 step을 R번 반복한다.
4.
R 개의 값을 사용하여 신뢰구간을 구한다.
그리고 이를 머신러닝 방식에 적용하면 다음과 같이 활용할 수 있다.
1.
m 개의 샘플이 있는 데이터 세트 D에서 m개를 복원 추출하여 D’를 만든다.
2.
D’를 훈련 데이터로, D-D’를 테스트 데이터 세트로 사용한다.
위와 같은 방식이 활용될 수 있는 이유는 m번의 복원 추출 과정을 살펴보면 알 수 있다.
m 번의 복원 추출 과정 중 어떠한 샘플이 한 번도 뽑히지 않을 확률은 이다. 그리고 극한값을 계산하면,
즉, 부트스트래핑을 사용하면 원래 데이터 세트 D 중에 36.8% 정도의 샘플은 D’에 들어가지 못한다는 것이다.
이러한 테스트를 Out-of-Bag이라고 한다.