
1. 모형 구분 단계
•
고객을 grouping 하고 규모와 업종을 나누는 단계
•
규모를 나누는 나누는 방법은 매출액, 총자산, 중소기업법기준 등이 있음
•
규모를 나누는 방법 중 하나를 선택하기 위해 Chow test를 수행
•
Chow test: 서로 다른 데이터에 대한 두 선형회귀식의 true coefficient 값들이 같은지를 확인하는 test.
•
예를 들어, 매출액, 총자산을 50개 구간으로 나누고, 각 구간을 기준으로 하위집단과 상위집단의 재무비율의 기울기의 동일 여부를 테스트(chow test)한다. 두 집단간 기울기가 달라지는 break point를 탐색하여 가장 많은 구간을 규모 구분 기준으로 선택.
•
모형 구분의 예:
◦
규모: 외감 대기업, 외감 중기업, 비외감 기업
◦
업종: 경공업, 중공업, IT, 건설업, 유통업, 서비스업
•
규모와 업종별로 구분한 후, 거의 대부분 규모별로는 별도의 모형을 만들고, 업종별로는 모형 내에서 부도율 산출을 위한 변수를 다르게 사용함.
2. 단순 회귀 분석 단계
•
실무에서 이 단계를 단변량 분석(univariate analysis) 단계라고 많이 함.
•
100 여개의 재무비율에서 40~50개를 선택하는 단계
◦
재무비율을 정렬하여 50개 구간으로 등분함
◦
각 구간별 부도업체 수를 산출: 구간별 부도율(ODR)
◦
재무비율과 부도율 간의 회귀분석 실시
◦
각 재무비율과 부도율간의 변별력 테스트를 측정하여 후보 비율을 선정
◦
같이 사용할 수 있는 테스트 방법
▪
AR(Accuracy Test)
▪
T-Test(특정재무비율이 정상차주 집단과 부도차주 집단에 미치는 영향 test)
▪
Wilcoxon test(비모수적 T-test)
3. 변수 제거 단계
•
40~50개의 중복 변수를 제거하고, 10~15개를 선택
•
상관관계 분석 (Correlation Analysis)
◦
재무비율 간에 상관관계 분석을 실시하여 유사한 중복 변수 제거
•
Default Frequency Line(DFL)을 통한 변수 선정
◦
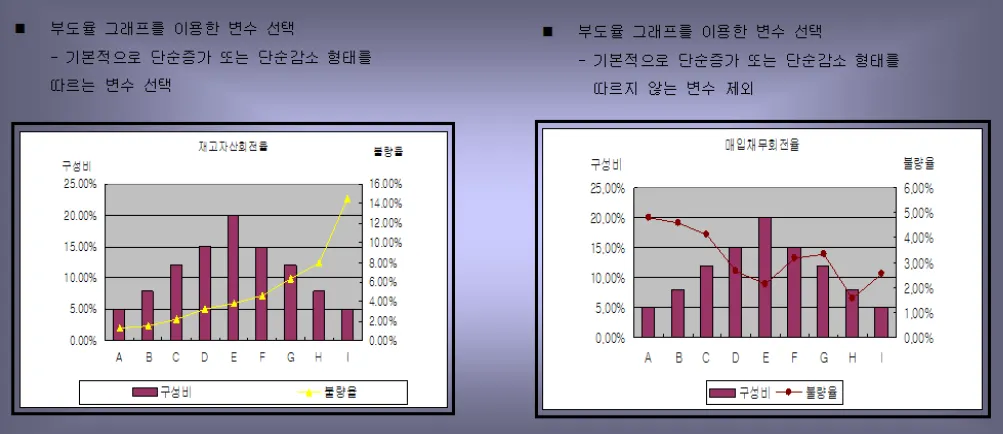
재무비율 별로 9개 구간으로 나누어, 각 차주의 구성비는 종 모양(평균 부분에 가장 많고, 각 구간 끝 부분에 적은 모양)이고, 각 구간별 부도율을 산출한 후, 부도율은 단조 증가 상태인 재무비율을 선택. → 즉, 재무비율에 따른 부도율이 단조 증가 또는 단조 감소인 변수 선택
◦
예시
4. 다중회귀분석 단계
•
실무에서는 다변량 분석(multivariate analysis) 단계라는 용어로 부름.
•
3 번째 단계를 거쳐서 최종 선정된 5~10개의 변수와 PD와의 관계를 분석함.
•
통계적 방법은 대표적으로 3가지가 있다.
◦
로짓 모형(로지스틱 회귀분석, Logistic Regression)
◦
신용평점 모형
◦
인공신경망 모형
•
가장 일반적으로 사용되는 것은 로짓 모형 (Logit Model)
Logistic Regression
Logistic Regression에서 PD값은 다음과 같다.
이때 는 선택된 재무비율
업종별 dummy 변수는 업종별 intercept 값이 다르므로, 이를 반영한 것.
5. 적합성 검증 단계
•
변별력 검증
◦
부도차주와 정상차주를 사전에 구별하는 능력
◦
상위 등급의 실제 부도율과 하위 등급의 실제 부도율간의 차이가 클수록 변별력이 큼
◦
대표적 지표: AR, K-S
•
안정성 검증
◦
안정성이 낮은 모형은 시간이 갈수록 변별력이 급격히 낮아짐
◦
시간 경과에 따른 모집단의 분포 변화 점검
◦
대표적 지표: PSI(Population Stability Index)
•
적합성 검증은 적합도 검증(goodness of fit test)을 포함하는 포괄적 의미로 사용
AR(Accuracy Ratio)
신용평가모형에는 세 가지 종류가 있음.
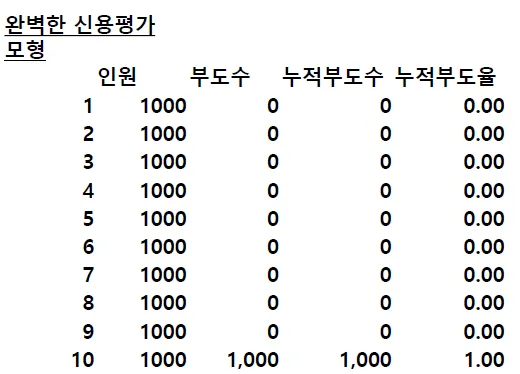
1.
100% 변별력이 있는 완전한 모형
•
향후 모든 부도날 차주를 사전에 100% 확인.
•
현실에는 없음.
2.
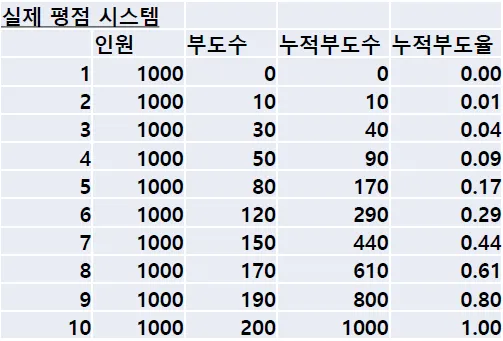
실무적 변별력 모형
•
높은 신용점수를 받는 차주 집단에서는 부도 차주의 비율이 적고, 낮은 신용점수를 받는 차주 집단으로 갈수록 부도 차주 비율이 높아지는 모형.
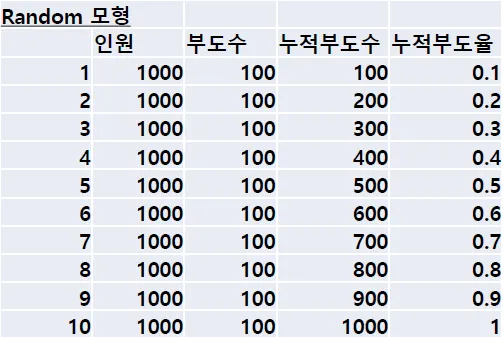
3.
변별력이 없는 모형 (random 모형)
•
높은 신용점수를 받는 차주 집단이나, 낮은 신용점수를 받는 차주 집단이나, 부도 차주의 비율이 동일한 모형
•
CAP(Cumulative Accuracy Profile) Curve와 AR
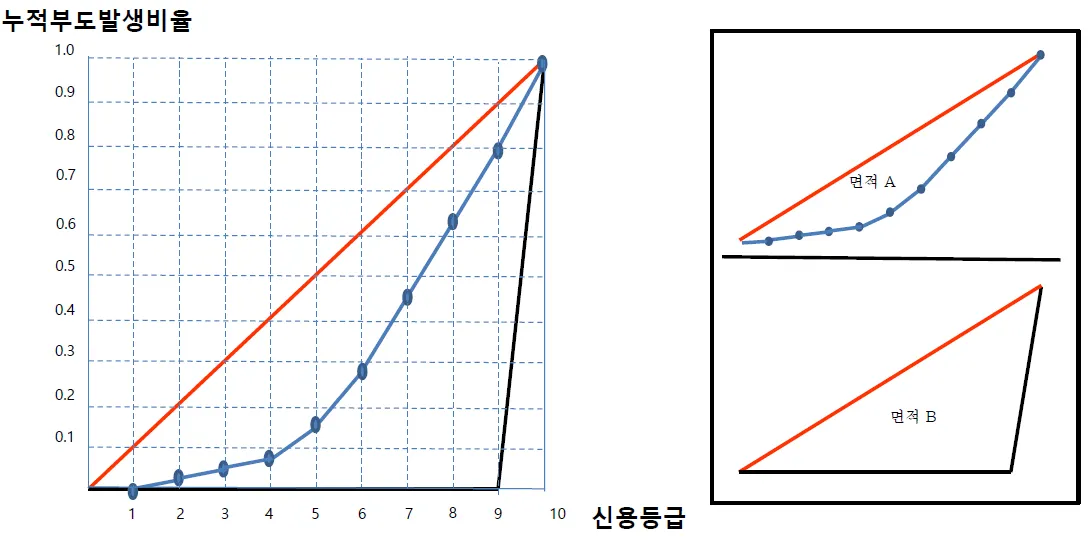
→ 주황색: random 모형 / 파란색: 실무적 변별력 모형 / 검은색: 완벽한 신용평가 모형
→ AR(Accuracy Ratio) = 면적 A / 면적 B
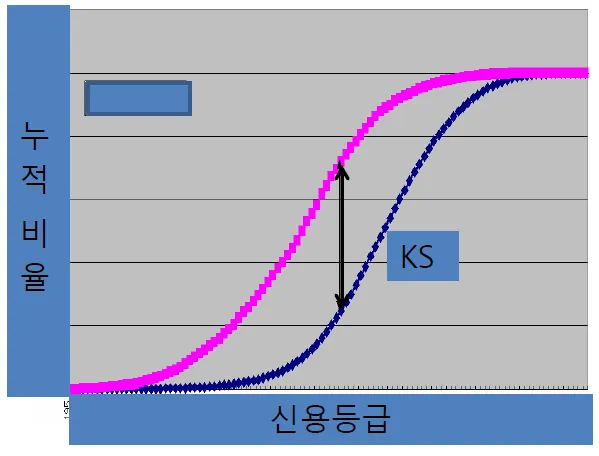
K-S(Komogorov-Smirnov)
•
우량 고객과 불량 고객 누적 비율 분포의 최대 차이
•
두 누적 분포 간 차이가 클수록 변별력이 양호한 것으로 간주.
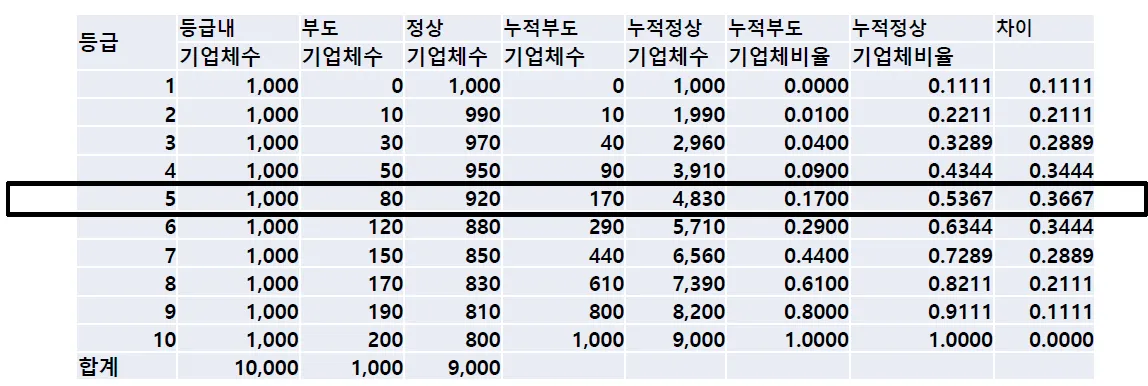
•
예를 들어 아래의 표에서 K-S 지표 값은 36.67%
PSI(Population Stability Index)
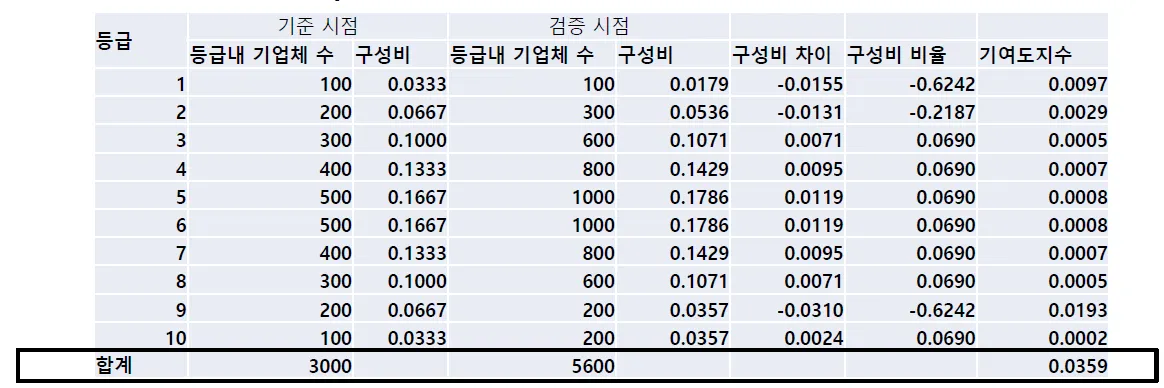
•
PSI는 시간 경과에 따른 모집단 분포의 변화를 계량화한 지표
•
이때 : 검증시점 구성비율, : 기준시점 구성비율
•
아래의 표에서 PSI는 3.59%
•
기준 예시) 안정적: PSI ≤ 10%, 주의: 10% < PSI ≤ 25%, 불안정적: PSI > 25%
•
카이제곱 검증을 통해서 안정성 검증을 할 수도 있다.