

목차
문제
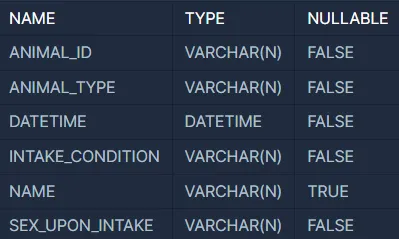
ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다.
ANIMAL_INS 테이블 구조는 다음과 같으며,
ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPON_INTAKE
는 각각 동물의 아이디, 생물 종, 보호 시작일, 보호 시작 시 상태, 이름, 성별 및 중성화 여부를 나타냅니다.
동물 보호소에 들어온 동물의 이름은 몇 개인지 조회하는 SQL 문을 작성해주세요. 이때 이름이 NULL인 경우는 집계하지 않으며 중복되는 이름은 하나로 칩니다.
예시
예를 들어 ANIMAL_INS 테이블이 다음과 같다면

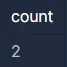
보호소에 들어온 동물의 이름은 NULL(없음), *Sam, *Sam, *Sweetie입니다. 이 중 NULL과 중복되는 이름을 고려하면, 보호소에 들어온 동물 이름의 수는 2입니다. 따라서 SQL문을 실행하면 다음과 같이 나와야 합니다.
정답
SELECT COUNT(NAME) FROM (SELECT DISTINCT NAME FROM ANIMAL_INS)
SQL
복사
풀이
•
중복되는 값을 제거하는 방법을 묻는 문제이다.
•
SELECT 절 바로 뒤에 DISTINCT를 넣으면 중복되는 행은 조회되지 않는다.
•
이때 NULL 값 또한 조회에서 제외된다.
•
따라서 NAME을 중복을 제외하고 조회한 뒤 그 테이블을 다시 COUNT() 함수를 사용하여 조회하면 unique한 NAME의 개수를 출력할 수 있다.