
문제
이번 추석에도 시스템 장애가 없는 명절을 보내고 싶은 어피치는 서버를 증설해야 할지 고민이다. 장애 대비용 서버 증설 여부를 결정하기 위해 작년 추석 기간인 9월 15일 로그 데이터를 분석한 후 초당 최대 처리량을 계산해보기로 했다. 초당 최대 처리량은 요청의 응답 완료 여부에 관계없이 임의 시간부터 1초(=1,000밀리초)간 처리하는 요청의 최대 개수를 의미한다.
입력
•
solution 함수에 전달되는 lines 배열은 N(1 ≦ N ≦ 2,000)개의 로그 문자열로 되어 있으며, 각 로그 문자열마다 요청에 대한 응답완료시간 S와 처리시간 T가 공백으로 구분되어 있다.
•
응답완료시간 S는 작년 추석인 2016년 9월 15일만 포함하여 고정 길이 2016-09-15 hh:mm:ss.sss 형식으로 되어 있다.
•
처리시간 T는 0.1s, 0.312s, 2s 와 같이 최대 소수점 셋째 자리까지 기록하며 뒤에는 초 단위를 의미하는 s로 끝난다.
•
예를 들어, 로그 문자열 2016-09-15 03:10:33.020 0.011s은 "2016년 9월 15일 오전 3시 10분 33.010초"부터 "2016년 9월 15일 오전 3시 10분 33.020초"까지 "0.011초" 동안 처리된 요청을 의미한다. (처리시간은 시작시간과 끝시간을 포함)
•
서버에는 타임아웃이 3초로 적용되어 있기 때문에 처리시간은 0.001 ≦ T ≦ 3.000이다.
•
lines 배열은 응답완료시간 S를 기준으로 오름차순 정렬되어 있다.
출력
• solution 함수에서는 로그 데이터 lines 배열에 대해 초당 최대 처리량을 리턴한다.
예시1
입력
[
"2016-09-15 01:00:04.001 2.0s",
"2016-09-15 01:00:07.000 2s"
]
Python
복사
출력
1
Plain Text
복사
예시2
입력
[
"2016-09-15 01:00:04.002 2.0s",
"2016-09-15 01:00:07.000 2s"
]
Python
복사
출력
2
Plain Text
복사
예시3
입력
[
"2016-09-15 20:59:57.421 0.351s",
"2016-09-15 20:59:58.233 1.181s",
"2016-09-15 20:59:58.299 0.8s",
"2016-09-15 20:59:58.688 1.041s",
"2016-09-15 20:59:59.591 1.412s",
"2016-09-15 21:00:00.464 1.466s",
"2016-09-15 21:00:00.741 1.581s",
"2016-09-15 21:00:00.748 2.31s",
"2016-09-15 21:00:00.966 0.381s",
"2016-09-15 21:00:02.066 2.62s"
]
Python
복사
출력
7
Plain Text
복사
정답
# milesecond를 기준으로 시작 시간과 끝 시간을 정의
def str_to_time(log):
hour = int(log[11:13]) * 3600
minute = int(log[14:16]) * 60
second = int(log[17:19])
end = (hour+minute+second) * 1000 + int(log[20:23])
elapse = int(float(log[24:-1])*1000)
start = end-elapse+1 # 시작 시간과 끝 시간 포함이기 때문에 1을 제하고 빼줌
return start, end
def solution(lines):
answer = 0
time_lines = []
for log in lines:
time_lines.append(str_to_time(log))
for i in range(len(time_lines)):
search_start = time_lines[i][1] # 검색 첫 시간
search_end = search_start + 999 # 검색 끝 시간
cnt = 0
for s, e in time_lines[i:]: # 끝 시간 기준 오름차순 정렬이기 때문에 i 번째 이후로만 살펴보아도 됨
if (e >= search_start) & (s <= search_end): # 끝 시간이 검색 시작 시간보다 크거나 같고 시작 시간이 검색 끝 시간보다 작거나 같으면 포함
cnt += 1
answer = max(answer, cnt) # 지금까지 나온 값들 중 가장 크면 answer로 채택
return answer
Python
복사
풀이
•
우선 가장 먼저 해야 할 것은 타임 라인을 milesecond 기준으로 재정의하고 시작 시간과 끝 시간을 구하는 것이다. 왜냐하면 milesecond를 기준으로 처리 시간이 정의 되어 있기 때문.
# milesecond를 기준으로 시작 시간과 끝 시간을 정의
def str_to_time(log):
hour = int(log[11:13]) * 3600
minute = int(log[14:16]) * 60
second = int(log[17:19])
end = (hour+minute+second) * 1000 + int(log[20:23])
elapse = int(float(log[24:-1])*1000)
start = end-elapse+1 # 시작 시간과 끝 시간 포함이기 때문에 1을 제하고 빼줌
return start, end
Python
복사
•
이때 주의할 것은 처리 시간은 시작 시간과 끝 시간을 포함하기 때문에 시작 시간을 구하려면 단순히 경과 시간을 빼주는 것이 아니라 경과 시간에서 1을 제하고 빼주어야 한다. 시작 시간 = 끝 시간 - 경과시간 + 1
•
다음은 1초 구간을 잡아서 그 구간 안에 포함되는 로그들의 합을 구해야 한다.
•
그런데 중요한 것은 1초 구간을 잡는 기준이다.
•
가장 먼저 생각해볼 수 있는 것은 로그의 가장 맨 처음 시작 시간과 끝 시간을 구해서 milesecond 단위로 움직이면서 모든 1초 구간을 탐색하는 방법이다.
하지만 가장 간단하지만 가장 오래 걸리기 때문에 시간 초과가 나는 방법이다.
•
이 문제에서 정답은 각 로그들의 끝 시간을 검색 구간의 시작 시간으로 잡는 것이다.
•
예시를 들어보자.
•
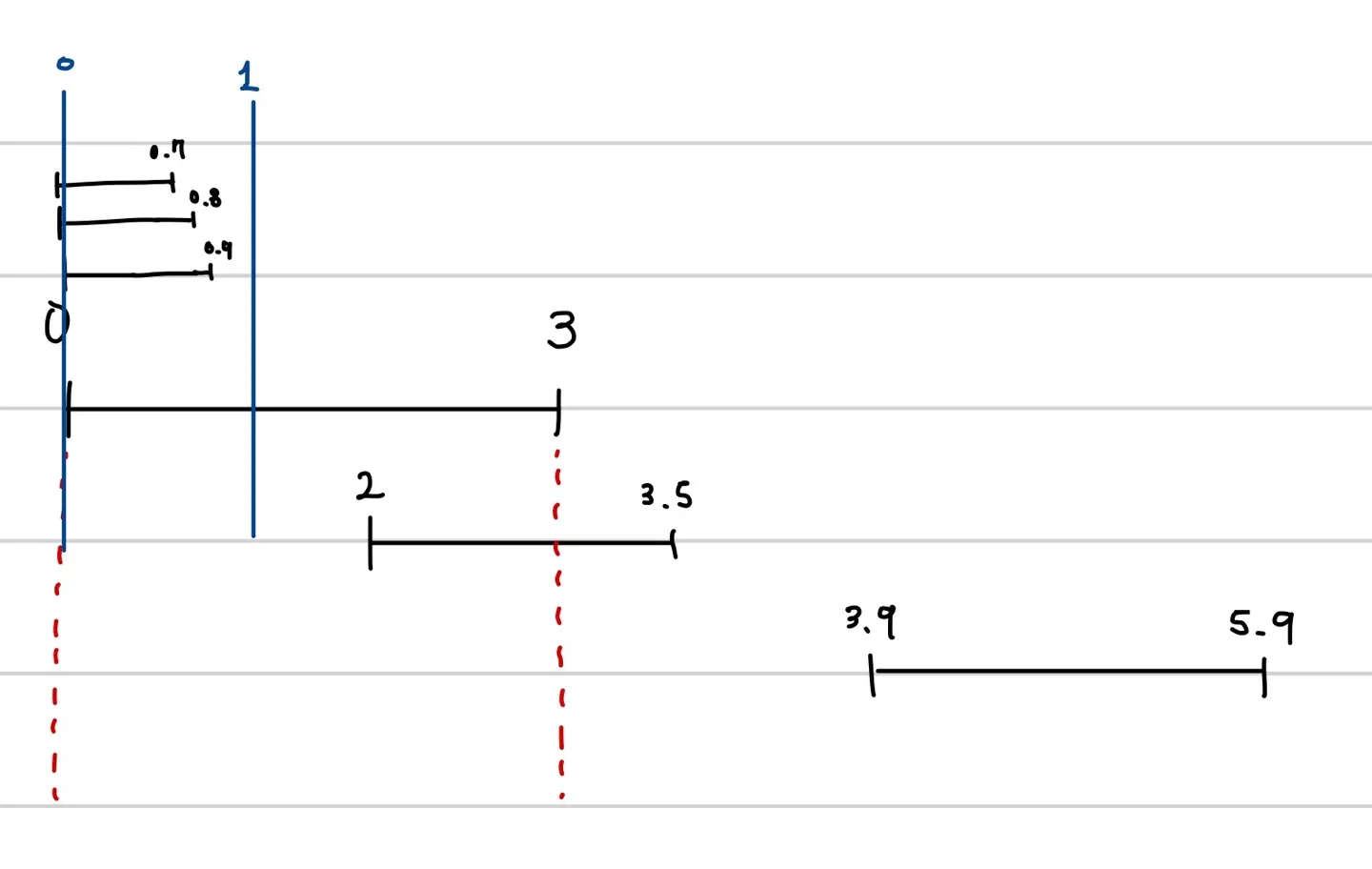
다음과 같이 로그가 있다고 하자. (이때 단위는 초라고 하자)
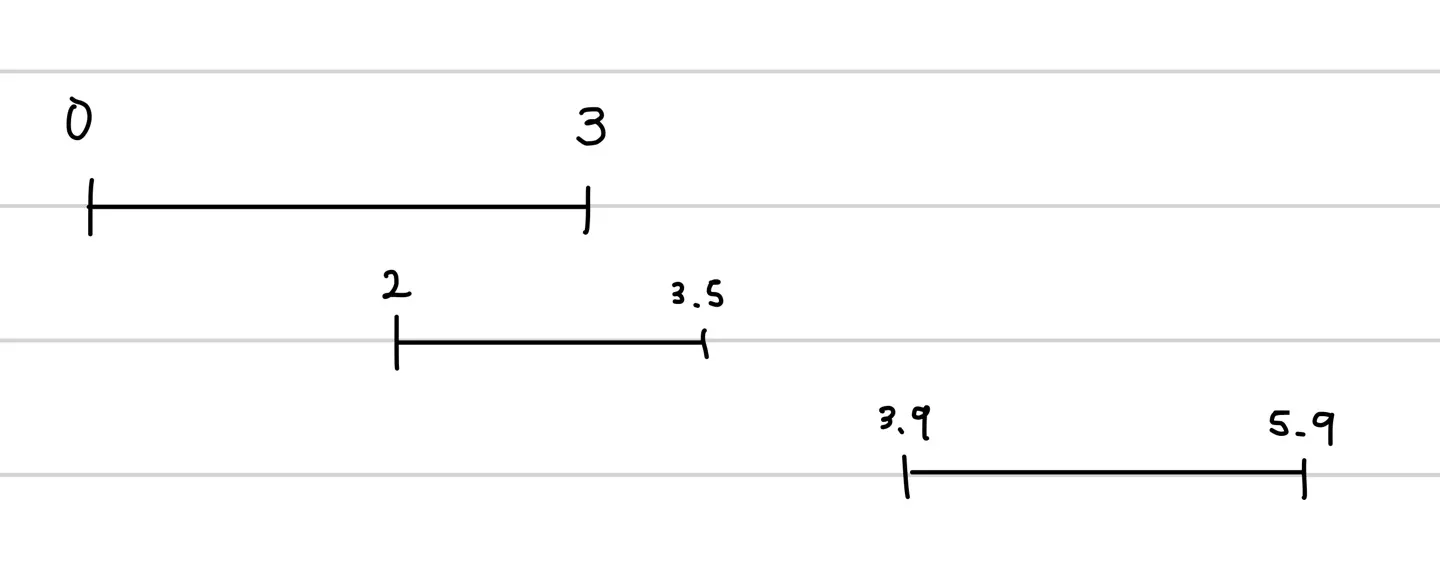
•
이 때 0~3 구간을 구간1이라고 하자.
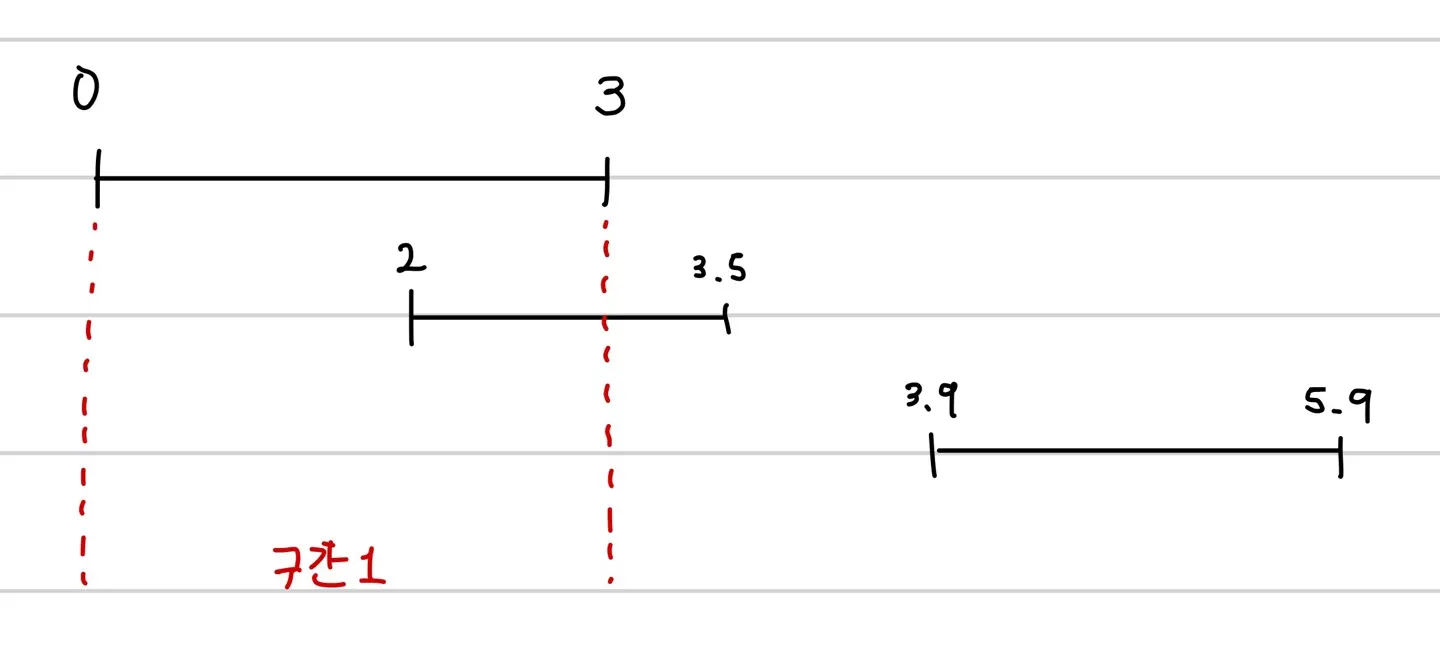
•
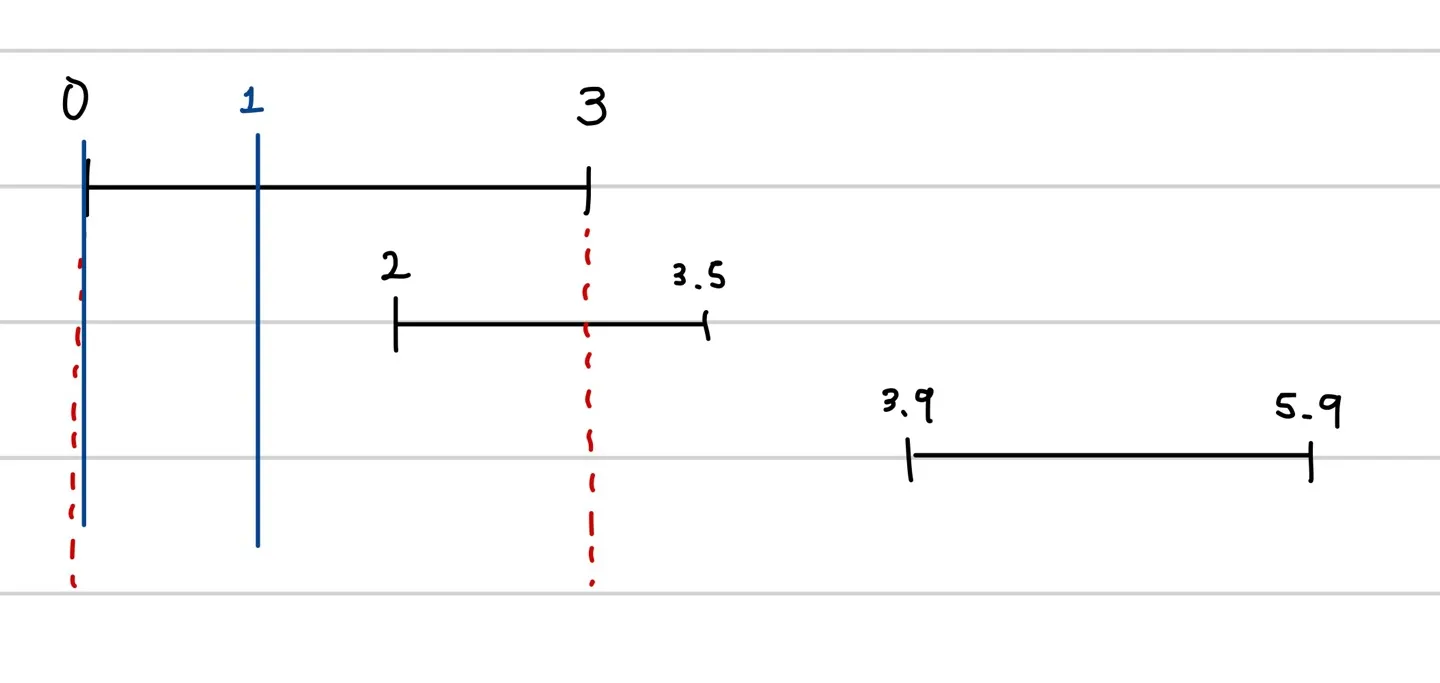
구간1에서 1초 검색 구간의 시작점은 0에서부터 3초까지이다. 예컨데 0초를 검색 구간의 시작으로 잡으면 다음과 같을 것이다. 파란색이 검색의 시작과 끝을 나타낸다.
•
우리는 끝 시간이 오름차순으로 정렬되어 있기 때문에 검색 구간을 오른쪽으로 옮기면 옮길수록 포함되는 로그들은 늘어난다(적어도 줄어들지 않는다). 따라서 검색 구간의 시작점을 오른쪽 맨 끝인 3으로 옮기는 것이 구간1에서 가장 좋다.
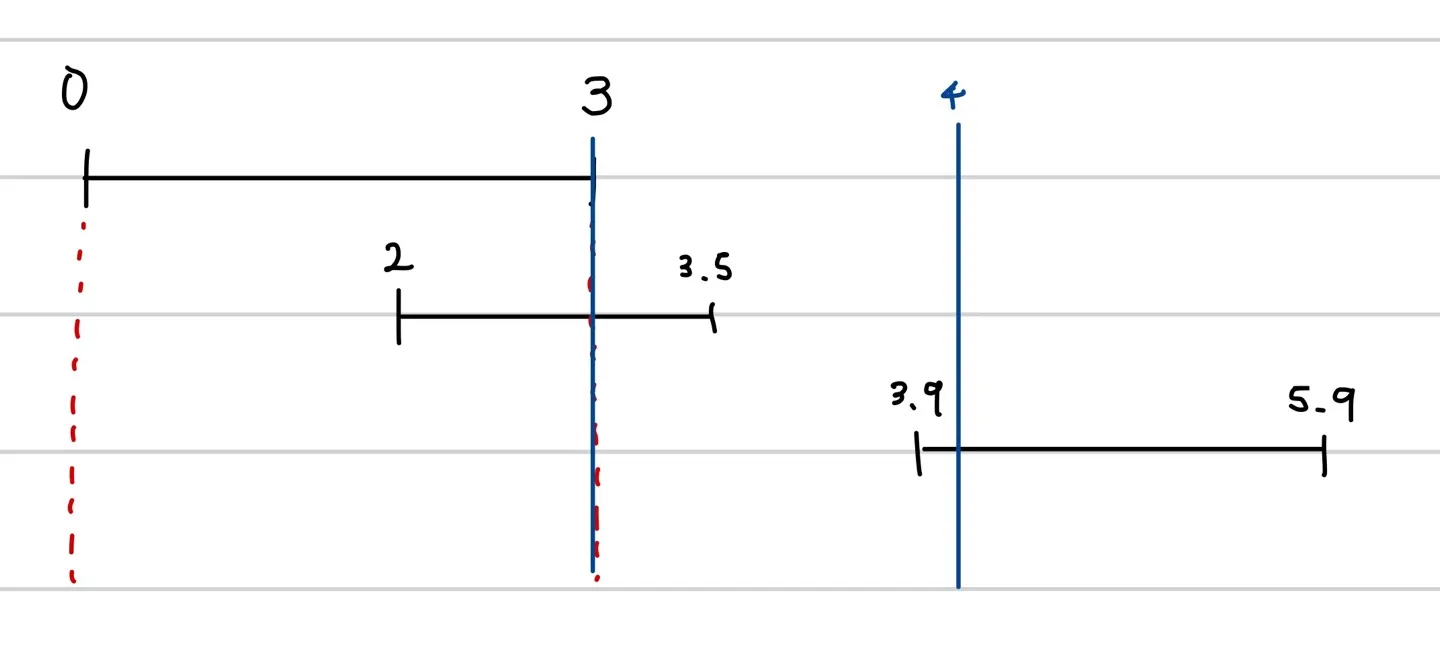
•
단, 0~3 이전에 로그가 없는 경우에 가장 좋다는 것이다. 만약 0~3 이전에 로그가 있다면 다음과 같이 구간1에서 가장 구간은 3~4가 아닐 수 있다.
•
하지만 이미 0~0.7구간에서 동일한 방식으로 0.7을 기준으로 삼아서 검색을 수행한다면 0~0.7에서 가장 좋은 시작점은 0.7임을 우리는 알고 있다. 즉, 이전 로그 구간에서 최적값은 이미 이전 로그에서 구했으므로 우리는 고려할 필요가 없는 것이다. 이 때문에 우리는 지금 현재 로그에서의 최적값만을 찾으면 된다. (따라서 Greedy 방식이다.)
•
결론적으로 각 로그 구간에서 검색 구간의 시작점의 최적점은 각 로그 구간의 끝 점이다.
•
그럼 이제 각 로그에서 끝점을 검색 구간의 시작점으로 두고 1초 내에 몇 개가 cnt가 되는지를 세주면 된다.
•
가장 먼저 로그들을 milesecond로 바꾸는 작업을 해준다.
def solution(lines):
answer = 0
time_lines = []
for log in lines:
time_lines.append(str_to_time(log))
Python
복사
•
그 다음 milesecond로 바뀐 구간들에 대하여 두 번째 값인 끝 점을 검색 구간의 시작점으로 잡고 검색 끝 시간은 999를 더해준다. (1000(1초)이 아니라 999를 더하는 이유는 시작과 끝 점을 모두 시간에 포함시키기 때문이다. 예를 들어, 5000 milesecond를 시작점으로 두었을 때 1초 후는 5999이다.)
for i in range(len(time_lines)):
search_start = time_lines[i][1] # 검색 첫 시간
search_end = search_start + 999 # 검색 끝 시간
Python
복사
•
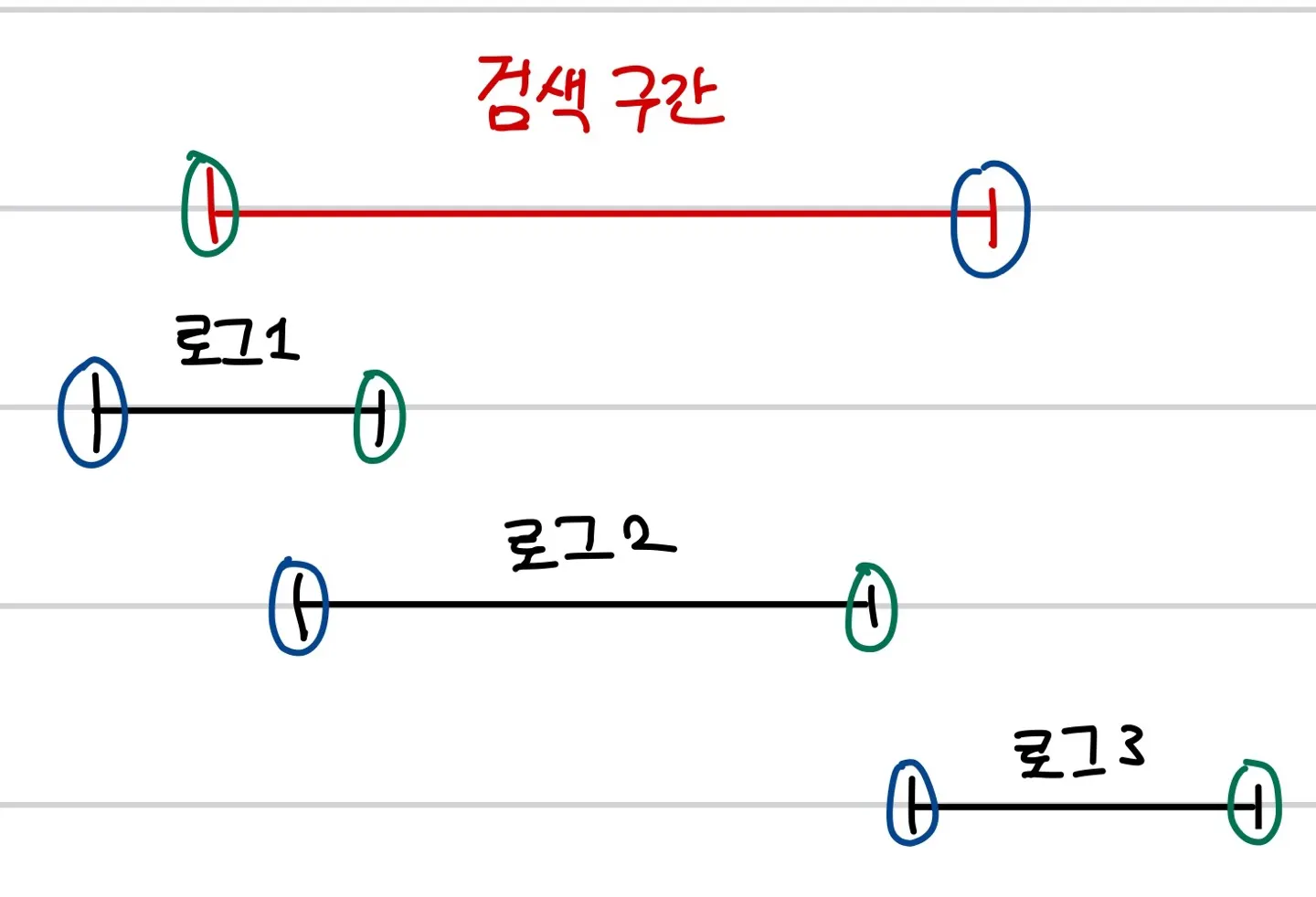
그 다음 구간 안에 로그가 포함되는 경우는 다음과 같다.
1.
로그의 끝 시간이 검색 시작 시간보다 크거나 같아야 한다.
2.
로그의 시작 시간이 검색 끝 시간보다 작거나 같아야 한다.
•
그리고 검색의 대상이 되는 로그들은 현재 기준이 되는 로그보다 끝 시간이 더 나중인 로그들만 찾으면 된다. 왜냐하면 그 이전인 로그들은 위에서 1 조건을 만족하지 못하기 때문이다.
for s, e in time_lines[i:]:
Python
복사
for s, e in time_lines[i:]: # 끝 시간 기준 오름차순 정렬이기 때문에 i 번째 이후로만 살펴보아도 됨
if (e >= search_start) & (s <= search_end): # 끝 시간이 검색 시작 시간보다 크거나 같고 시작 시간이 검색 끝 시간보다 작거나 같으면 포함
cnt += 1
Python
복사
•
마지막으로 총 cnt의 값이 지금까지 나온 answer의 값보다 크다면 answer로 채택한다.
answer = max(answer, cnt) # 지금까지 나온 값들 중 가장 크면 answer로 채택
Python
복사
•
정리하면
1.
milesecond를 기준으로 시간 재정의
2.
answer 값 0으로 정의
3.
로그의 끝 점을 검색 구간의 시작 점으로 잡는다.
4.
검색 구간 내에 있는 로그들을 count 한다.
5.
count 값이 answer보다 크다면 answer로 채택한다.
6.
모든 로그에 대해서 step 3-5 수행