

문제
Amber's conglomerate corporation just acquired some new companies. Each of the companies follows this hierarchy:

Given the table schemas below, write a query to print the company_code, founder name, total number of lead managers, total number of senior managers, total number of managers, and total number of employees. Order your output by ascending company_code.
Note:
•
The tables may contain duplicate records.
•
The company_code is string, so the sorting should not be numeric. For example, if the company_codes are C_1, C_2, and C_10, then the ascending company_codes will be C_1, C_10, and C_2.
Input Format
The following tables contain company data:
•
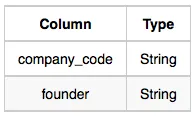
Company: The company_code is the code of the company and founder is the founder of the company.
•
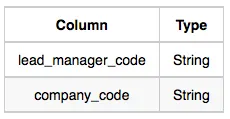
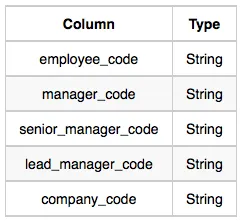
Lead_Manager: The lead_manager_code is the code of the lead manager, and the company_code is the code of the working company.
•
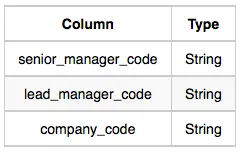
Senior_Manager: The senior_manager_code is the code of the senior manager, the lead_manager_code is the code of its lead manager, and the company_code is the code of the working company.
•
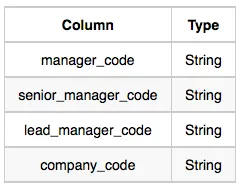
Manager: The manager_code is the code of the manager, the senior_manager_code is the code of its senior manager, the lead_manager_code is the code of its lead manager, and the company_code is the code of the working company.
•
Employee: The employee_code is the code of the employee, the manager_code is the code of its manager, the senior_manager_code is the code of its senior manager, the lead_manager_code is the code of its lead manager, and the company_code is the code of the working company.
예시
Sample Input
Company Table:

Lead_Manager Table:

Senior_Manager Table:
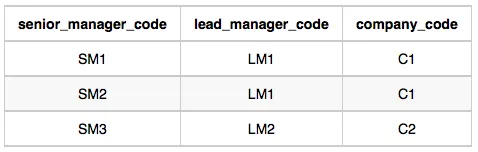
Manager Table:
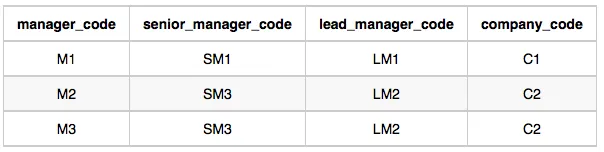
Employee Table:
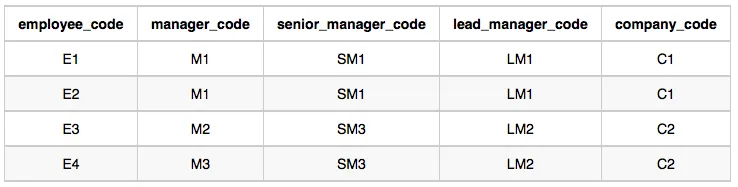
Sample Output
C1 Monika 1 2 1 2
C2 Samantha 1 1 2 2
Plain Text
복사
정답
1.
SELECT C.company_code,
C.founder,
COUNT(DISTINCT LM.lead_manager_code),
COUNT(DISTINCT SM.senior_manager_code),
COUNT(DISTINCT M.manager_code),
COUNT(DISTINCT E.employee_code)
FROM Company C
LEFT JOIN Lead_Manager LM ON C.company_code = LM.company_code
LEFT JOIN Senior_Manager SM ON LM.company_code = SM.company_code and LM.lead_manager_code = SM.lead_manager_code
LEFT JOIN Manager M on SM.company_code = M.company_code and SM.lead_manager_code = M.lead_manager_code and SM.senior_manager_code = M.senior_manager_code
LEFT JOIN Employee E on M.company_code = E.company_code and M.lead_manager_code = E.lead_manager_code and M.senior_manager_code = E.senior_manager_code and M.manager_code = E.manager_code
GROUP BY C.company_code, C.founder
ORDER BY C.company_code;
SQL
복사
2.
SELECT C.company_code, C.founder,
(SELECT COUNT(DISTINCT lead_manager_code) FROM Lead_Manager WHERE company_code = C.company_code),
(SELECT COUNT(DISTINCT senior_manager_code) FROM Senior_Manager WHERE company_code = C.company_code),
(SELECT COUNT(DISTINCT manager_code) FROM Manager WHERE company_code = C.company_code),
(SELECT COUNT(DISTINCT employee_code) FROM Employee WHERE company_code = C.company_code)
FROM Company C
ORDER BY company_code;
SQL
복사
풀이
1.
LEFT JOIN 활용
•
첫 번째 방법은 LEFT JOIN으로 계속해서 테이블을 묶어서 푸는 방식이다.
•
더 하위에 존재하는 테이블에 있는 필드값들은 상위에 있는 테이블에 존재하지 않는 필드를 제외하고는 전부 상위 테이블에 존재하는 점을 이용한다.
•
예를 들어 Manager Table은 Senior Manager Table의 하위 테이블이다. 이때 Manager에만 존재하는 필드인 manager_code를 제외하고 Manager Table에 존재하는 필드값들은 전부 Senior Manager Table 안에 존재한다.
•
하지만 그 역은 성립하지 않는다.
•
따라서 LEFT JOIN의 기준을 더 상위 테이블로 두면 자동으로 하위 직원이 없는 필드의 값들은 NULL 처리가 된다.
•
예를 들어서 예시의 Senior Table과 Manager Table을 Senior Table을 기준으로 LEFT JOIN하면 다음과 같다. 이때 JOIN의 기준들은 공통으로 들어있는 필드를 전부 선택하는 것이 좋다.(왜냐하면 집단 끼리 code가 겹치지 않는다는 보장이 없기 때문)

•
코드에서는 LEFT JOIN을 연속해서 사용할 수 있다.
FROM Company C
LEFT JOIN Lead_Manager LM ON C.company_code = LM.company_code
LEFT JOIN Senior_Manager SM ON LM.company_code = SM.company_code and LM.lead_manager_code = SM.lead_manager_code
LEFT JOIN Manager M on SM.company_code = M.company_code and SM.lead_manager_code = M.lead_manager_code and SM.senior_manager_code = M.senior_manager_code
LEFT JOIN Employee E on M.company_code = E.company_code and M.lead_manager_code = E.lead_manager_code and M.senior_manager_code = E.senior_manager_code and M.manager_code = E.manager_code
SQL
복사
→ C를 기준으로 Lead_Manager를 LEFT JOIN하고
→ 그 테이블을 기준으로 Senior_Manager를 LEFT JOIN하고 ....
•
그 다음 COUNT를 해주는데 문제에서 중복값이 존재할 수 있다고 했으므로 COUNT() 함수 내부에 DISTINCT를 써준다.
SELECT C.company_code,
C.founder,
COUNT(DISTINCT LM.lead_manager_code),
COUNT(DISTINCT SM.senior_manager_code),
COUNT(DISTINCT M.manager_code),
COUNT(DISTINCT E.employee_code)
SQL
복사
•
Company 별로 구해야 하므로 Company와 founder를 기준으로 grouping한다.
GROUP BY C.company_code, C.founder
SQL
복사
2.
SELECT 서브쿼리 활용
•
Company 테이블의 company_code가 pk이고 나머지 테이블들은 company_code를 fk로 참조하고 있다.
•
각 테이블에선 각 직업들의 총 수를 company 별로 구할 수 있다. 예를 들어 Manager 테이블에서는 각 기업들의 Manager의 수를 구할 수 있다.
•
이를 이용하여 select 문에 서브쿼리를 이용해서 답을 구할 수 있다.
•
이때 WHERE절을 활용하여 JOIN을 수행시켜준다.
(SELECT COUNT(DISTINCT lead_manager_code) FROM Lead_Manager WHERE company_code = C.company_code),
SQL
복사