
출처:


목차
1. Target Data 유무에 따른 구분
머신러닝의 종류를 구분하는 가장 기본적인 방법은 Target Data의 유무에 따라서 구분하는 방식이다.
1) 지도 학습(Supervised Learning)
정의
: 머신러닝을 통해서 프로그램을 만들기 위해 데이터의 샘플과 레이블(부가정보)을 주어 학습시키는 것을 의미한다.
여기서 레이블은 샘플의 부가정보이자 추후 새로운 데이터에서 알아내고 싶은 목표치(Target Data)이다.
즉, 지도학습의 목표는 수많은 샘플과 레이블 정보를 머신러닝 모델에 학습시켜 추후, 모델에 새로운 샘플 데이터가 들어왔을 때 레이블 정보를 예측하는 것이다.
모델 종류
1.
분류 (Classification)
데이터를 특정한 그룹으로 분류하는 것.
2.
회귀 (Regression)
특정한 Target Data의 값을 예측하는 것.
•
알고리즘 종류: KNN, Linear Regression, Logistic Regression, SVM, Decision Tree, Random Forest, Neural Network
2) 비지도 학습(Unsupervised Learning)
정의
: 지도학습과는 달리 레이블 없이 머신러닝 모델을 학습시키는 것을 의미한다. 데이터는 있지만 레이블이 없으므로 예측보단 주로 주어진 데이터들을 분석하는데 사용된다.
모델 종류
1.
군집 (Clustering)
데이터에 포함된 특징을 분석하고 연관된 특징끼리 나누어 그룹화를 진행하는 것을 의미한다. 분류(Classification)와 다른점은 분류는 정해진 레이블 즉, 답이 있는 반면 군집은 정해진 레이블이 없다.
•
알고리즘 종류: K-means, HCA(Hierarchical Cluster Analysis), Expectation Maximization
2.
시각화(Visualization)
레이블이 없는 고차원 데이터를 넣으면 도식화가 가능한 2D, 3D 모델을 만들어서 보여준다.
•
알고리즘 종류: t-SNE
3.
차원축소(Dimmensionality Reduction)
데이터에 너무 많은 부가정보(차원)가 있을 경우 이를 간소화 하되 데이터의 정보손실을 최소화 시키는 모델이다.
•
알고리즘 종류: 주성분 분석(PCA), Kernel PCA, 지역적 선형 임베딩(LLE)
4.
변칙 탐지(Anomaly Detection)
정상 샘플로 훈련된 모델을 사용하여 새로운 샘플이 정상적인 데이터인지 변칙된 이상치인지 파악한다.
5.
연관 규칙 학습(Association Rule Learning)
주어진 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 것을 의미한다.
•
알고리즘 종류: Apriori, Eclat
3) 준지도학습(Semisupervised Learning)
정의
: 학습하는 데이터가 대부분 레이블이 없지만 일부는 레이블이 있는 경우의 학습을 의미한다.
예를 들어, 구글 포토 호스팅의 경우 clustering을 통해 여러가지 사진에서 사람의 얼굴을 분석하여 똑같은 사람끼리 분류를 할 수 있다. 이때까지는 비지도 학습을 통해서 자체적으로 분류를 진행하지만 만약 새로 추가된 사진에 이미 분류했던 사람의 얼굴과 그 사람의 이름(레이블)이 올라왔을 경우 이미 군집된 샘플들을 통해서 지도 학습을 수행할 수 있다.
즉, 지도 학습과 비지도 학습의 혼합.
2. 강화학습(Reinforcement Learning)
정의
: 학습을 위한 시스템(에이전트)을 구축하고 시스템의 환경을 관찰하며 시스템의 행동에 따라 보상과 벌점을 주어 시스템이 최대한 많은 보상을 받도록 강화시키는 학습을 의미한다.
•
알고리즘 종류: GAN, AutoEncoder
3. 훈련 데이터의 스트림에 따른 구분
1) 배치학습
정의
: 입력스트림이 정적인 학습을 의미한다. 대량의 데이터를 순차적으로 모두 학습을 시킨 후 완성된 학습 모델을 더 이상의 학습을 하지 않고 실전에 투입된다. 보통 샘플 데이터의 갱신률이 낮은 정적 데이터의 경우 사용한다.
장점
•
데이터 모델링 시에 빌드 및 테스트가 쉽다. 새로운 데이터가 추가되었을 때 기존의 모델링을 위한 코드는 계속 유지하여 빌드를 하기 간편하고 기존의 모델과 비교를 통해서 테스트 하기도 간편하기 때문이다.
단점
•
새로운 데이터를 학습하기 위해서는 기존에 학습했던 데이터를 포함하여 전부 새로 학습해야 한다. 갱신률이 높을 경우에는 지속적으로 대량의 컴퓨터 자원을 중복해서 소모하기 때문에 비효율적일 수 있다.
2) 온라인 학습
정의
: 데이터를 순차적으로 한 개씩 또는 미니배치(mini-batch)라고 불리는 단위로 쪼개어 학습하는 것을 의미한다. 보통 데이터의 갱신률이 높은 동적 데이터의 경우 사용한다.
장점
•
mini-batch 단위로 데이터를 학습하기 때문에 한 번의 학습을 하는데 필요한 컴퓨팅 자원이 축소된다.
•
배치 학습과 달리 예전에 사용했던 데이터의 자료가 필요하지 않다.
•
갱신률이 높은 데이터의 경우 해당 데이터만 처리하면 되기 때문에 컴퓨팅 자원을 축소시킬 수 있다.
단점
•
실시간으로 업로드 되는 데이터가 모두 정확하다고 할 수 없다. 즉, 노이즈가 심한 데이터가 업로드 되는 경우 모델의 정확성을 낮출 수 있다.
•
모델의 정확성 저하를 방지하기 위해 따로 실시간으로 데이터를 감시해야 할 시스템을 구축해야 한다.
•
시스템의 추가 구축으로 인한 복잡성 증가와 더불어 에러 및 버그를 지속적으로 수정해야 될 필요성이 있다.
4. 모델 일반화 방식에 따른 구분
머신러닝 시스템을 나누는 또 한 가지의 요소는 어떻게 모델을 일반화 할 것인가이다. 일반화란 시스템이 훈련데이터를 계속 학습하여 추후 새로운 데이터가 들어온 경우 이를 정확히 판단할 수 있는 것을 의미한다.
1) 사례 기반 학습
정의
: 사례 기반 학습은 시스템이 지금까지 학습했던 모든 훈련데이터를 기억하고 이에 기반하여 새로운 데이터를 판단하는 것을 의미한다.
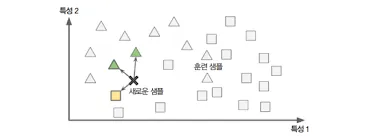
새로운 데이터와 기존의 데이터를 비교하여 어느 쪽이 더 가까운지 유사도를 계산, 판단하는 것이 사례 기반 학습이다.
2) 모델 기반 학습
정의
: 모델 기반 학습은 훈련 데이터를 통해 일반화를 위한 기준(모델)을 만들고 이를 통해서 새로운 데이터를 판단하는 것을 의미한다.
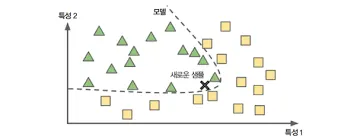
사례 기반의 경우 새로운 데이터가 들어온 경우 매번 유사도를 계산해야 하기 때문에 컴퓨팅 자원이 많이 소모되어 시간이 많이 걸릴 수 있지만 모델 기반의 학습은 모델을 통해 새로운 데이터가 어느 영역에 있는지 단번에 알 수 있기 때문에 빠르게 판단이 가능하다.