
목차
출처

1. 개요
이상치란 대부분의 값들의 범위에서 크게 벗어난 값을 의미한다.
이상치를 판단하는 기준은 z-score, IQR(Interquantile Range), Isolation Forest, DBScan 방식들이 있다.
2. z-score
데이터의 분포가 정규 분포를 이루는 경우 데이터의 표준 편차를 활용하여 이상치를 탐지할 수 있다.
•
: data
•
: mean
•
: standard deviation
이라고 할 때, z-score 공식은 다음과 같다.
해석하면, 데이터가 평균으로부터 얼마의 표준 편차만큼 벗어나있는지를 의미한다. 보통 절댓값을 기준으로 3을 초과하면 이상치로 분류한다.
3. IQR(Interquantile Range)
데이터의 분포가 정규 분포를 이루지 않거나 한 쪽으로 치우친(skewed) 경우 사용한다.
•
Q1: 하위 25% 지점
•
Q3: 상위 25% 지점
이라고 할 때, IQR 값은 Q3-Q1을 의미한다.
이때 보다 작거나 보다 큰 경우 이상치로 간주한다. 1.5 대신 다른 수를 곱할 수도 있다.

4. Isolation Forest
결정 트리 계열의 비지도 학습 알고리즘으로 이상치를 탐지하는 방식이다. High dimensional 데이터셋에서 이상치를 탐지할 때 효과적이다.
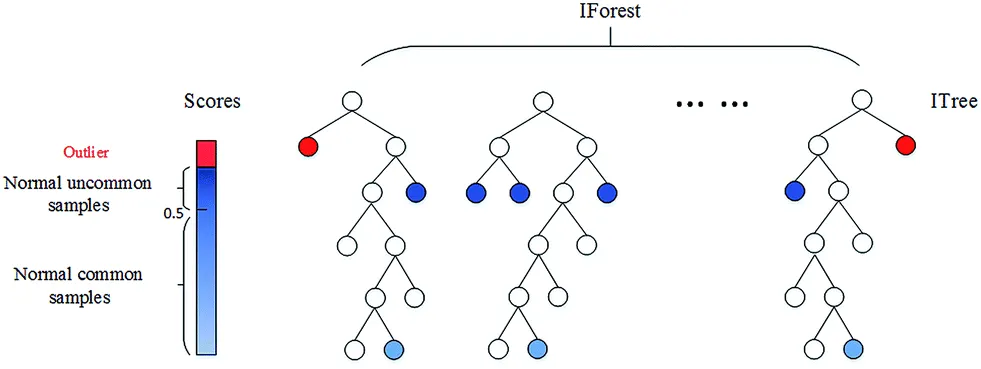
원리는 데이터셋을 결정 트리 형태로 표현할 때 이상치는 트리의 상단에서 쉽게 분리할 수 있다는 점을 이용한다. 루트 노드까지의 평균 거리가 짧을 수록 outlier score가 높아지도록 score를 설정하여 outlier score가 높을수록 이상치라고 간주한다.
이때 는 기존 leaf node 깊이에 c를 더해 보정한 이후의 전체 나무에 대한 평균 길이를 의미하고, 는 평균경로길이를 보정해주기 위한 각 데이터 별로 정의된 상수값이다.
5. DBScan(Density Based Spatial Clustering of Applications with Noise)
DBScan은 밀도 기반의 클러스터링 알고리즘으로 어떠한 클러스터에도 포함되지 않는 데이터를 표시해준다는 특징이 있다. 따라서 DBScan 방식을 통해 어떠한 클러스터에도 포함되지 않는 데이터를 이상치로 간주하는 방식이다.