
문제
여러 언론사에서 쏟아지는 뉴스, 특히 속보성 뉴스를 보면 비슷비슷한 제목의 기사가 많아 정작 필요한 기사를 찾기가 어렵다. Daum 뉴스의 개발 업무를 맡게 된 신입사원 튜브는 사용자들이 편리하게 다양한 뉴스를 찾아볼 수 있도록 문제점을 개선하는 업무를 맡게 되었다.
개발의 방향을 잡기 위해 튜브는 우선 최근 화제가 되고 있는 "카카오 신입 개발자 공채" 관련 기사를 검색해보았다.
•
카카오 첫 공채..'블라인드' 방식 채용
•
카카오, 합병 후 첫 공채.. 블라인드 전형으로 개발자 채용
•
카카오, 블라인드 전형으로 신입 개발자 공채
•
카카오 공채, 신입 개발자 코딩 능력만 본다
•
카카오, 신입 공채.. "코딩 실력만 본다"
•
카카오 "코딩 능력만으로 2018 신입 개발자 뽑는다"
기사의 제목을 기준으로 "블라인드 전형"에 주목하는 기사와 "코딩 테스트"에 주목하는 기사로 나뉘는 걸 발견했다. 튜브는 이들을 각각 묶어서 보여주면 카카오 공채 관련 기사를 찾아보는 사용자에게 유용할 듯싶었다.
유사한 기사를 묶는 기준을 정하기 위해서 논문과 자료를 조사하던 튜브는 "자카드 유사도"라는 방법을 찾아냈다.
자카드 유사도는 집합 간의 유사도를 검사하는 여러 방법 중의 하나로 알려져 있다. 두 집합 A, B 사이의 자카드 유사도 J(A, B)는 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의된다.
예를 들어 집합 A = {1, 2, 3}, 집합 B = {2, 3, 4}라고 할 때, 교집합 A ∩ B = {2, 3}, 합집합 A ∪ B = {1, 2, 3, 4}이 되므로, 집합 A, B 사이의 자카드 유사도 J(A, B) = 2/4 = 0.5가 된다. 집합 A와 집합 B가 모두 공집합일 경우에는 나눗셈이 정의되지 않으니 따로 J(A, B) = 1로 정의한다.
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해서 확장할 수 있다. 다중집합 A는 원소 "1"을 3개 가지고 있고, 다중집합 B는 원소 "1"을 5개 가지고 있다고 하자. 이 다중집합의 교집합 A ∩ B는 원소 "1"을 min(3, 5)인 3개, 합집합 A ∪ B는 원소 "1"을 max(3, 5)인 5개 가지게 된다. 다중집합 A = {1, 1, 2, 2, 3}, 다중집합 B = {1, 2, 2, 4, 5}라고 하면, 교집합 A ∩ B = {1, 2, 2}, 합집합 A ∪ B = {1, 1, 2, 2, 3, 4, 5}가 되므로, 자카드 유사도 J(A, B) = 3/7, 약 0.42가 된다.
이를 이용하여 문자열 사이의 유사도를 계산하는데 이용할 수 있다. 문자열 "FRANCE"와 "FRENCH"가 주어졌을 때, 이를 두 글자씩 끊어서 다중집합을 만들 수 있다. 각각 {FR, RA, AN, NC, CE}, {FR, RE, EN, NC, CH}가 되며, 교집합은 {FR, NC}, 합집합은 {FR, RA, AN, NC, CE, RE, EN, CH}가 되므로, 두 문자열 사이의 자카드 유사도 J("FRANCE", "FRENCH") = 2/8 = 0.25가 된다.
입력
•
입력으로는 str1과 str2의 두 문자열이 들어온다. 각 문자열의 길이는 2 이상, 1,000 이하이다.
•
입력으로 들어온 문자열은 두 글자씩 끊어서 다중집합의 원소로 만든다. 이때 영문자로 된 글자 쌍만 유효하고, 기타 공백이나 숫자, 특수 문자가 들어있는 경우는 그 글자 쌍을 버린다. 예를 들어 "ab+"가 입력으로 들어오면, "ab"만 다중집합의 원소로 삼고, "b+"는 버린다.
•
다중집합 원소 사이를 비교할 때, 대문자와 소문자의 차이는 무시한다. "AB"와 "Ab", "ab"는 같은 원소로 취급한다.
출력
입력으로 들어온 두 문자열의 자카드 유사도를 출력한다. 유사도 값은 0에서 1 사이의 실수이므로, 이를 다루기 쉽도록 65536을 곱한 후에 소수점 아래를 버리고 정수부만 출력한다.
예시
입출력
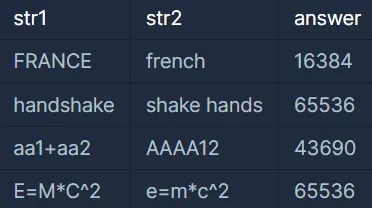
정답
1.
숫자로만 풀기
def solution(str1, str2):
str1 = str1.lower() # 대소문자 구분이 없으므로 소문자로 통일
str2 = str2.lower()
split_list1 = [] # 다중집합 만들기
split_list2 = []
for i in range(len(str1)-1):
if str1[i:i+2].isalpha(): # 알파벳인 원소들만 포함
split_list1.append(str1[i:i+2])
for i in range(len(str2)-1):
if str2[i:i+2].isalpha():
split_list2.append(str2[i:i+2])
# 두 집합 모두 공집합인 경우
if (len(split_list1) == 0) & (len(split_list2) == 0):
return 65536
intersect = set(split_list1) & set(split_list2) # unique 교집합
intersect_num = 0
for string in intersect:
intersect_num += min(split_list1.count(string), split_list2.count(string)) # 중복 포함 교집합 원소 개수
union_num = len(split_list1) + len(split_list2) - intersect_num # 중복 포함 합집합 개수
answer = int(intersect_num/union_num * 65536) # 자카드 유사도
return answer
Python
복사
2.
값을 구해서 풀기
def solution(str1, str2):
str1 = str1.lower() # 대소문자 구분 없으므로 소문자로 통일
str2 = str2.lower()
split_dict1 = dict() # 다중집합 만들기
split_dict2 = dict()
for i in range(len(str1)-1):
if str1[i:i+2].isalpha():
if str1[i:i+2] not in split_dict1:
split_dict1[str1[i:i+2]] = 1
else:
split_dict1[str1[i:i+2]] += 1
for i in range(len(str2)-1):
if str2[i:i+2].isalpha():
if str2[i:i+2] not in split_dict2:
split_dict2[str2[i:i+2]] = 1
else:
split_dict2[str2[i:i+2]] += 1
# 두 집합 모두 공집합인 경우
if (len(split_dict1) == 0) & (len(split_dict2) == 0):
return 65536
# 중복 포함 교집합, 합집합 구하기
intersect = dict()
union = dict()
for string in split_dict1:
if string in split_dict2:
intersect[string] = min(split_dict1[string], split_dict2[string]) # 교집합
union[string] = max(split_dict1[string], split_dict2[string]) # 교집합에 포함되는 원소는 합집합에 포함됨. 그리고 그 값은 min이 아니라 max로 들어감
else:
union[string] = split_dict1[string] # str1에만 포함되는 원소
for string in split_dict2:
if string not in split_dict1:
union[string] = split_dict2[string] # str2에만 포함되는 원소
answer = int(sum(intersect.values()) / sum(union.values()) * 65536) # 자카드 유사도
return answer
Python
복사
풀이
숫자로만 풀기
•
가장 먼저 해야 하는 것은 다중집합을 만드는 것이다.
•
우선 대문자와 소문자의 차이는 무시하기 때문에 전부 소문자로 통일해준다.
def solution(str1, str2):
str1 = str1.lower() # 대소문자 구분이 없으므로 소문자로 통일
str2 = str2.lower()
Python
복사
•
그 다음 다중집합을 만들 리스트를 설정한다.
str1_list = [] # 다중집합 만들기
str2_list = []
Python
복사
•
다중집합을 만드는 방법은 문자열의 왼쪽에서부터 한개씩 이동하면서 2개씩 확인하면서 알파벳만 이루어져있는지를 확인하고 알파벳으로만 이루어져 있으면 다중집합에 포함시키고 아니면 제외하면 된다. 특정 문자열이 알파벳으로만 이루어져 있는지를 확인하는 함수는 .isalpha()이다.
for i in range(len(str1)-1):
if str1[i:i+2].isalpha(): # 알파벳인 원소들만 포함
split_list1.append(str1[i:i+2])
for i in range(len(str2)-1):
if str2[i:i+2].isalpha():
split_list2.append(str2[i:i+2])
Python
복사
•
그 다음 만약 두 집합이 모두 공집합인 경우 자동으로 자카드 유사도가 무조건 1이기 때문에 65536을 return 한다.
# 두 집합 모두 공집합인 경우
if (len(split_list1) == 0) & (len(split_list2) == 0):
return 65536
Python
복사
•
그 다음 교집합의 수를 구한다.
•
교집합의 수를 구하기 위해서 우선 unique한 교집합의 원소를 구한다.
intersect = set(split_list1) & set(split_list2) # unique 교집합
Python
복사
•
그 다음 각각의 split_list에서 intersect 원소의 개수를 세고 더 작은 값을 교집합의 개수에 더해준다.
intersect_num = 0
for string in intersect:
intersect_num += min(split_list1.count(string), split_list2.count(string)) # 중복 포함 교집합 원소 개수
Python
복사
•
중복을 포함하는 합집합의 개수는 각각의 split_list의 길이(각각의 다중집합의 원소 개수)를 더한 뒤 중복 포함 교집합의 원소의 개수를 빼주면 된다.
union_num = len(split_list1) + len(split_list2) - intersect_num # 중복 포함 합집합 개수
Python
복사
•
마지막으로 자카드 유사도를 조건에 맞게 구해준다.
answer = int(intersect_num/union_num * 65536) # 자카드 유사도
Python
복사
값을 구해서 풀기
•
위에서는 list로 다중집합을 구해주었지만 여기서는 시간 단축을 위해서 dictionary로 구해주었다. 이때 key값은 unique한 원소를 의미하고 value값은 그 원소가 몇 개 포함되어있는지를 나타낸다.
def solution(str1, str2):
str1 = str1.lower() # 대소문자 구분이 없으므로 소문자로 통일
str2 = str2.lower()
split_dict1 = dict() # 다중집합 만들기 (key: unique한 원소 / value: 포함된 원소의 개수)
split_dict2 = dict()
for i in range(len(str1)-1):
if str1[i:i+2].isalpha():
if str1[i:i+2] not in split_dict1: # dictionary에 없는 경우 추가
split_dict1[str1[i:i+2]] = 1
else:
split_dict1[str1[i:i+2]] += 1 # dictionary에 이미 있는 경우 1을 더해줌.
for i in range(len(str2)-1):
if str2[i:i+2].isalpha():
if str2[i:i+2] not in split_dict2:
split_dict2[str2[i:i+2]] = 1
else:
split_dict2[str2[i:i+2]] += 1
Python
복사
•
마찬가지로 둘 다 공집합인 경우는 65536을 return
# 두 집합 모두 공집합인 경우
if (len(split_dict1) == 0) & (len(split_dict2) == 0):
return 65536
Python
복사
•
교집합의 경우 split_dict1에 항상 포함된다는 점을 이용한다.
◦
만약 split_dict1의 원소가 split_dict2에도 포함된다면 교집합 원소로 간주하고 split_dict1에서의 value 값과 split_dict2에서의 value 값을 확인하여 더 작은 값을 value로 교집합의 dictionary에 포함해준다. 그리고 더 큰 값을 value로 합집합의 dictionary에 포함시켜준다.
◦
만약 split_dict1의 원소가 split_dict2에 포함되지 않으면 split_dict1에만 포함되는 원소이므로 split_dict1의 value값을 확인하여 union dictionary에만 포함시켜준다.
◦
그 다음 split_dict2의 원소 중 split_dict1에 포함되지 않는 원소 값들만 확인하여 union dictionary에 포함시켜준다.
intersect = dict()
union = dict()
for string in split_dict1:
if string in split_dict2: # 교집합 원소에 포함되는 경우
intersect[string] = min(split_dict1[string], split_dict2[string])
union[string] = max(split_dict1[string], split_dict2[string])
else: # split_dict1에만 포함되는 경우
union[string] = split_dict1[string]
for string in split_dict2: # split_dict2에만 포함되는 경우
if string not in split_dict1:
union[string] = split_dict2[string]
Python
복사
•
intersect의 value 값을 전부 더하면 교집합의 개수이고 union의 value 값을 전부 더하면 합집합의 개수이다. 이를 이용하여 자카드 유사도를 구한다.
answer = int(sum(intersect.values()) / sum(union.values()) * 65536)
Python
복사