

문제
Pivot the Occupation column in OCCUPATIONS so that each Name is sorted alphabetically and displayed underneath its corresponding Occupation. The output column headers should be Doctor, Professor, Singer, and Actor, respectively.
Note: Print NULL when there are no more names corresponding to an occupation.
Input Format
The OCCUPATIONS table is described as follows:

Occupation will only contain one of the following values: Doctor, Professor, Singer or Actor.
예시
Sample Input
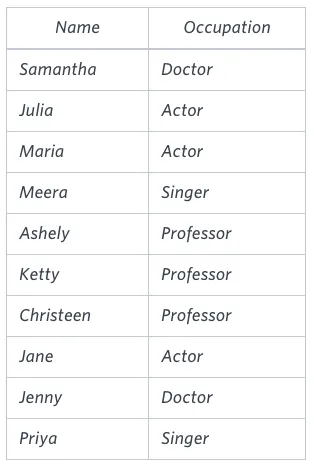
Sample Output
Jenny Ashley Meera Jane
Samantha Christeen Priya Julia
NULL Ketty NULL Maria
Plain Text
복사
정답
SET @r1=0, @r2=0, @r3=0, @r4=0;
SELECT MAX(Doctor), MAX(Professor), MAX(Singer), MAX(Actor)
FROM(
SELECT
CASE WHEN Occupation = 'Doctor' THEN Name END AS Doctor,
CASE WHEN Occupation = 'Professor' THEN Name END AS Professor,
CASE WHEN Occupation = 'Singer' THEN Name END AS Singer,
CASE WHEN Occupation = 'Actor' THEN Name END AS Actor,
CASE
WHEN Occupation = 'Doctor' THEN @r1 := @r1+1
WHEN Occupation = 'Professor' THEN @r2 := @r2+1
WHEN Occupation = 'Singer' THEN @r3 := @r3+1
ELSE @r4 := @r4+1
END As RowNumber
FROM OCCUPATIONS
ORDER BY Name) TEMP
GROUP BY RowNumber
;
SQL
복사
풀이
•
전역변수와 CASE WHEN 사용법에 관한 문제이다.
•
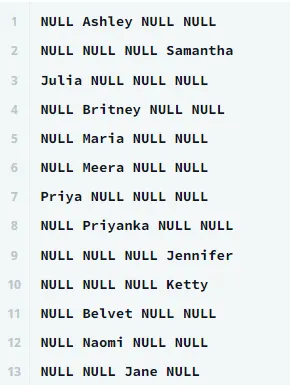
일단 다음과 같이 쿼리를 짜는 경우
SELECT
CASE WHEN Occupation = 'Doctor' THEN Name END as Doctor,
CASE WHEN Occupation = 'Professor' THEN Name END as Professor,
CASE WHEN Occupation = 'Singer' THEN Name END as Singer,
CASE WHEN Occupation = 'Actor' THEN Name END as Actor
FROM OCCUPATIONS;
SQL
복사
•
이런식으로 결과가 나온다.
•
순서대로 Doctor, Professor, Singer, Actor 필드인데, OCCUPATIONS 테이블의 데이터를 위에서부터 차례로 살피면서 해당 직업과 일치하면 Name을, 아니면 NULL을 출력한다.
•
CASE WHEN의 경우 어떠한 조건에도 일치하지 않는 값이 나오면(즉, ELSE를 사용하지 않으면) NULL 값을 출력한다.
•
이제 맨 마지막 줄에 이름이 출력된 사람의 직업이 지금까지 몇 개 나왔는지를 나타내는 필드를 새로 생성해서 출력해보자.
SET @r1=0, @r2=0, @r3=0, @r4=0;
SELECT
CASE WHEN Occupation = 'Doctor' THEN Name END AS Doctor,
CASE WHEN Occupation = 'Professor' THEN Name END AS Professor,
CASE WHEN Occupation = 'Singer' THEN Name END AS Singer,
CASE WHEN Occupation = 'Actor' THEN Name END AS Actor,
CASE
WHEN Occupation = 'Doctor' THEN @r1 := @r1+1
WHEN Occupation = 'Professor' THEN @r2 := @r2+1
WHEN Occupation = 'Singer' THEN @r3 := @r3+1
ELSE @r4 := @r4+1
END As RowNumber
FROM OCCUPATIONS
ORDER BY Name;
SQL
복사
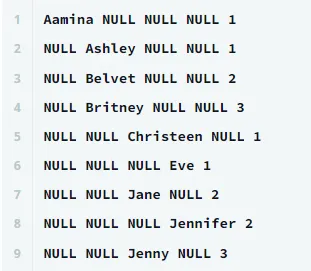
→ NULL Belvet NULL NULL의 경우 지금까지 Professor가 두 번 나왔기 때문에 2로 나온다.
•
그럼 이제 RowNumber를 기준으로 Group을 지으면 각 직업별로 최대 한 명의 이름만 있고 나머지는 NULL인 상태가 될 것이다. 예를 들어 RowNumber를 기준으로 Grouping을 했을 때 RowNumber가 1인 그룹은 다음과 같은 형태일 것이다.
Aamina NULL NULL NULL
NULL Ashley NULL NULL
NULL NULL Christeen NULL
NULL NULL NULL Eve
SQL
복사
•
따라서 이제 각 필드별로 집계함수를 이용해서 출력을 해주어야 하는데, MIN() 또는 MAX() 함수를 사용하면 된다. 집계 함수를 사용해야 하는 이유는 Group By를 사용하면 항상 집계 함수를 사용해주어야 되기 때문이다. 그리고 집계함수는 NULL을 제외하고 작동하기 때문에 NULL이 아닌 값이 하나이므로 MIN() 또는 MAX()를 이용해서 출력하면 된다.
SET @r1=0, @r2=0, @r3=0, @r4=0;
SELECT MAX(Doctor), MAX(Professor), MAX(Singer), MAX(Actor)
FROM(
SELECT
CASE WHEN Occupation = 'Doctor' THEN Name END AS Doctor,
CASE WHEN Occupation = 'Professor' THEN Name END AS Professor,
CASE WHEN Occupation = 'Singer' THEN Name END AS Singer,
CASE WHEN Occupation = 'Actor' THEN Name END AS Actor,
CASE
WHEN Occupation = 'Doctor' THEN @r1 := @r1+1
WHEN Occupation = 'Professor' THEN @r2 := @r2+1
WHEN Occupation = 'Singer' THEN @r3 := @r3+1
ELSE @r4 := @r4+1
END As RowNumber
FROM OCCUPATIONS
ORDER BY Name) TEMP
GROUP BY RowNumber
;
SQL
복사