
문제
프렌즈 대학교 조교였던 제이지는 허드렛일만 시키는 네오 학과장님의 마수에서 벗어나, 카카오에 입사하게 되었다.평소에 관심있어하던 검색에 마침 결원이 발생하여, 검색개발팀에 편입될 수 있었고, 대망의 첫 프로젝트를 맡게 되었다.그 프로젝트는 검색어에 가장 잘 맞는 웹페이지를 보여주기 위해 아래와 같은 규칙으로 검색어에 대한 웹페이지의 매칭점수를 계산 하는 것이었다.
•
한 웹페이지에 대해서 기본점수, 외부 링크 수, 링크점수, 그리고 매칭점수를 구할 수 있다.
•
한 웹페이지의 기본점수는 해당 웹페이지의 텍스트 중, 검색어가 등장하는 횟수이다. (대소문자 무시)
•
한 웹페이지의 외부 링크 수는 해당 웹페이지에서 다른 외부 페이지로 연결된 링크의 개수이다.
•
한 웹페이지의 링크점수는 해당 웹페이지로 링크가 걸린 다른 웹페이지의 기본점수 ÷ 외부 링크 수의 총합이다.
•
한 웹페이지의 매칭점수는 기본점수와 링크점수의 합으로 계산한다.
예를 들어, 다음과 같이 A, B, C 세 개의 웹페이지가 있고, 검색어가 hi라고 하자.
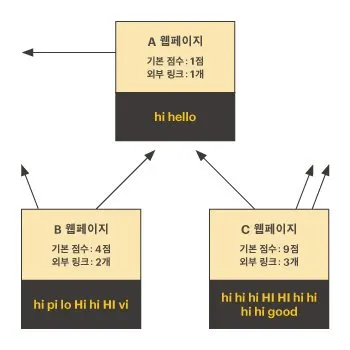
이때 A 웹페이지의 매칭점수는 다음과 같이 계산할 수 있다.
•
기본 점수는 각 웹페이지에서 hi가 등장한 횟수이다.
◦
A,B,C 웹페이지의 기본점수는 각각 1점, 4점, 9점이다.
•
외부 링크수는 다른 웹페이지로 링크가 걸린 개수이다.
◦
A,B,C 웹페이지의 외부 링크 수는 각각 1점, 2점, 3점이다.
•
A 웹페이지로 링크가 걸린 페이지는 B와 C가 있다.
◦
A 웹페이지의 링크점수는 B의 링크점수 2점(4 ÷ 2)과 C의 링크점수 3점(9 ÷ 3)을 더한 5점이 된다.
•
그러므로, A 웹페이지의 매칭점수는 기본점수 1점 + 링크점수 5점 = 6점이 된다.
검색어 word와 웹페이지의 HTML 목록인 pages가 주어졌을 때, 매칭점수가 가장 높은 웹페이지의 index를 구하라. 만약 그런 웹페이지가 여러 개라면 그중 번호가 가장 작은 것을 구하라.
제한 사항
•
pages는 HTML 형식의 웹페이지가 문자열 형태로 들어있는 배열이고, 길이는 1 이상 20 이하이다.
•
한 웹페이지 문자열의 길이는 1 이상 1,500 이하이다.
•
웹페이지의 index는 pages 배열의 index와 같으며 0부터 시작한다.
•
한 웹페이지의 url은 HTML의 태그 내에 태그의 값으로 주어진다.
◦
예를들어, 아래와 같은 meta tag가 있으면 이 웹페이지의 url은 https://careers.kakao.com/index 이다.
◦
<meta property="og:url" content="https://careers.kakao.com/index" />
•
한 웹페이지에서 모든 외부 링크는 <a href="https://careers.kakao.com/index">의 형태를 가진다.
◦
<a> 내에 다른 attribute가 주어지는 경우는 없으며 항상 href로 연결할 사이트의 url만 포함된다.
◦
위의 경우에서 해당 웹페이지는 https://careers.kakao.com/index 로 외부링크를 가지고 있다고 볼 수 있다.
•
모든 url은 https:// 로만 시작한다.
•
검색어 word는 하나의 영어 단어로만 주어지며 알파벳 소문자와 대문자로만 이루어져 있다.
•
word의 길이는 1 이상 12 이하이다.
•
검색어를 찾을 때, 대소문자 구분은 무시하고 찾는다.
◦
예를들어 검색어가 blind일 때, HTML 내에 Blind라는 단어가 있거나, BLIND라는 단어가 있으면 두 경우 모두 해당된다.
•
검색어는 단어 단위로 비교하며, 단어와 완전히 일치하는 경우에만 기본 점수에 반영한다.
◦
단어는 알파벳을 제외한 다른 모든 문자로 구분한다.
◦
예를들어 검색어가 "aba" 일 때, "abab abababa"는 단어 단위로 일치하는게 없으니, 기본 점수는 0점이 된다.
◦
만약 검색어가 "aba" 라면, "aba@aba aba"는 단어 단위로 세개가 일치하므로, 기본 점수는 3점이다.
•
결과를 돌려줄때, 동일한 매칭점수를 가진 웹페이지가 여러 개라면 그중 index 번호가 가장 작은 것를 리턴한다
◦
즉, 웹페이지가 세개이고, 각각 매칭점수가 3,1,3 이라면 제일 적은 index 번호인 0을 리턴하면 된다.
예시1
입력
•
word: blind
•
pages:
["<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://a.com\"/>\n</head> \n<body>\nBlind Lorem Blind ipsum dolor Blind test sit amet, consectetur adipiscing elit. \n<a href=\"https://b.com\"> Link to b </a>\n</body>\n</html>", "<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://b.com\"/>\n</head> \n<body>\nSuspendisse potenti. Vivamus venenatis tellus non turpis bibendum, \n<a href=\"https://a.com\"> Link to a </a>\nblind sed congue urna varius. Suspendisse feugiat nisl ligula, quis malesuada felis hendrerit ut.\n<a href=\"https://c.com\"> Link to c </a>\n</body>\n</html>", "<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://c.com\"/>\n</head> \n<body>\nUt condimentum urna at felis sodales rutrum. Sed dapibus cursus diam, non interdum nulla tempor nec. Phasellus rutrum enim at orci consectetu blind\n<a href=\"https://a.com\"> Link to a </a>\n</body>\n</html>"]
Plain Text
복사
출력
0
Plain Text
복사
예시2
입력
•
word: Muzi
•
pages:
["<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://careers.kakao.com/interview/list\"/>\n</head> \n<body>\n<a href=\"https://programmers.co.kr/learn/courses/4673\"></a>#!MuziMuzi!)jayg07con&&\n\n</body>\n</html>", "<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://www.kakaocorp.com\"/>\n</head> \n<body>\ncon%\tmuzI92apeach&2<a href=\"https://hashcode.co.kr/tos\"></a>\n\n\t^\n</body>\n</html>"]
Plain Text
복사
출력
1
Plain Text
복사
정답
import re
def solution(word, pages):
word = word.lower() # 소문자로 검색
score_dict = dict() # 각 url 별 기본 점수 및 링크 페이지 등을 담은 dictionary
for index, page in enumerate(pages):
# url
url = re.search('<meta property="og:url" content="(\S+)"', page).group(1) # '<meta property="og:url" content="(\S+)"'를 찾고 소괄호 부분(url) 만 빼오기
#외부 링크
out_pages = re.findall('<a href="(https://[\S]*)"', page) # '<a href="(https://[\S]*)"' 를 찾고 소괄호 부분만 출력
# 기본점수 구하기
d_score = 0
for w in re.findall(f'[a-zA-Z]+', page.lower()): # page 내의 모든 단어 찾기, 단어의 기준: 알파벳으로만 구성
if w == word: # 일치하면 +1
d_score += 1
score_dict[url] = [index, d_score, out_pages, 0] # index, 기본점수, 외부링크, 링크점수
# 링크 점수 구하기
for page in score_dict:
out_pages = score_dict[page][2]
if len(out_pages) == 0: # 외부 링크가 없는 경우
continue
else:
l_score = score_dict[page][1] / len(out_pages) # 현재 url이 줄 수 있는 링크 점수
for out_page in out_pages:
if out_page in score_dict: # 외부링크가 dictionary에 존재하는 경우 링크 점수 부여
score_dict[out_page][3] += l_score
# 총 점수별로 내림차순, index 순으로 오름차순
sorted_dict = sorted(score_dict.items(), key = lambda x: (-(x[1][1] + x[1][3]), x[1][0]))
return sorted_dict[0][1][0] # index 출력
Python
복사
풀이
•
정규식을 활용해야 하는 문제이다.
•
우선 각 웹페이지 별로 url과 기본 점수 등을 담고 있는 dictionary를 만들어서 문제를 풀자.
•
찾고자 하는 단어의 경우 대소문자 구분이 없으므로 소문자로 통일한다.
def solution(word, pages):
word = word.lower() # 소문자로 검색
score_dict = dict() # 각 url 별 기본 점수 및 링크 페이지 등을 담은 dictionary
Python
복사
•
각 웹사이트의 url은 항상 '<meta property="og:url" content=’ 뒤에 붙는다. 따라서 필요한 정규식은 '<meta property="og:url" content="(\S+)"' 이다. 이때 \S는 공백이 아닌 모든 문자를 의미하고 +는 한 개 이상의 문자를 의미한다. 그리고 소괄호를 이용하여 캡처 기능을 사용한다.
url = re.search('<meta property="og:url" content="(\S+)"', page).group(1) # '<meta property="og:url" content="(\S+)"'를 찾고 소괄호 부분(url) 만 빼오기
Python
복사
→ re.search('<meta property="og:url" content="(\S+)"', page) 를 사용하면 '<meta property="og:url" content="(\S+)"' 부분 전체가 찾아지기 때문에 .group(1) 메서드를 통해서 괄호부분만 따로 빼온다.
•
외부 링크의 경우 여러 개가 존재할 수 있다. 따라서 findall을 사용해야 한다.
•
외부 링크는 '<a href=https://’ 로 시작하고 중간에 링크가 들어가고 “로 끝난다. 따라서 다음의 정규식을 사용한다.
out_pages = re.findall('<a href="(https://[\S]*)"', page) # '<a href="(https://[\S]*)"' 를 찾고 소괄호 부분만 출력
Python
복사
→ findall은 group을 사용하지 않더라도 소괄호 캡처 기능을 자동으로 사용한다.
•
기본 점수의 경우 우선 페이지 내의 모든 단어를 찾고 주어진 word와 일치하는 지를 확인하면 된다.
•
문제에 의하면 단어의 기준은 공백없이 알파벳으로만 구성된 것을 의미한다. 예를 들어 muzI123에서는 muzi가 단어이고 MuziMuzi에서는 muzimuzi가 단어이다. 따라서 연속되는 모든 알파벳을 의미하는 정규식인 [a-zA-Z]+을 이용하여 모든 단어를 찾고 word와의 일치 여부를 확인해서 기본 점수를 구한다.
# 기본점수 구하기
d_score = 0
for w in re.findall(f'[a-zA-Z]+', page.lower()): # page 내의 모든 단어 찾기, 단어의 기준: 알파벳으로만 구성
if w == word: # 일치하면 +1
d_score += 1
Python
복사
•
그 다음 url을 key로 갖고 index, 기본점수, 외부링크, 링크점수를 value로 갖도록 dictionary를 만든다.
score_dict[url] = [index, d_score, out_pages, 0] # index, 기본점수, 외부링크, 링크점수
Python
복사
•
다음으로 링크 점수를 구한다.
•
dictionary를 활용하여 각 웹사이트들의 외부 링크를 우선 확인한다. 그리고 외부 링크들 중에 dictionary에 있는 웹사이트가 있다면 그 외부 링크에 현재 웹사이트가 줄 수 있는 링크 점수를 더해준다. 현재 웹사이트가 줄 수 있는 링크 점수는 기본 점수 / 외부링크 수이다.
# 링크 점수 구하기
for page in score_dict:
out_pages = score_dict[page][2]
if len(out_pages) == 0: # 외부 링크가 없는 경우
continue
else:
l_score = score_dict[page][1] / len(out_pages) # 현재 url이 줄 수 있는 링크 점수
for out_page in out_pages:
if out_page in score_dict: # 외부링크가 dictionary에 존재하는 경우 링크 점수 부여
score_dict[out_page][3] += l_score
Python
복사
•
마지막으로 총 점수별로 내림차순하고 index 별로 오름차순하여 첫 번째 index를 출력한다.
# 총 점수별로 내림차순, index 순으로 오름차순
sorted_dict = sorted(score_dict.items(), key = lambda x: (-(x[1][1] + x[1][3]), x[1][0]))
return sorted_dict[0][1][0] # index 출력
Python
복사