
목차
출처


1. 개요
빅데이터의 경우 정규성 검정 결과를 무조건적으로 신뢰해서는 안 된다. 샘플 수가 많을수록 p-value가 작아져 실제 데이터의 분포와 관계없이 정규분포를 따르지 않는다는 검정 결과를 얻을 수 있기 때문이다.
2. 정규성 검정
정규성 검정에서의 귀무가설은 데이터가 정규성을 만족한다는 것이고 대립가설은 정규성을 만족하지 않는다는 것이다.
대표적인 정규성 검정들은 다음과 같다.
1.
Shapiro–Wilk test
2.
Kolmogorov–Smirnov test
3.
Q-Q Plot
3. 빅데이터에서 정규성 검정의 신뢰도
p-value를 기준으로 검정을 수행하는 Shapiro–Wilk test 과 Kolmogorov–Smirnov test의 경우 빅데이터에서의 정규성 검정은 신뢰도가 떨어진다. p-value는 샘플 수가 늘어날수록 작아지는 경향이 있기 때문이다. 즉, 데이터가 작을 경우에는 해당 데이터가 정규성을 따르는지 보기 위해 편차를 감지하는 능력이 부족한 반면, 데이터가 많을 경우에는 실질적으로는 문제가 되지 않는 사소한 편차도 감지한다.
이로 인해 정규분포의 형태를 띠고 있는 데이터임에도 막상 정규성 검정을 수행하면 귀무가설을 기각하는 현상이 발생한다. 예컨대 아래 4번째 Q-Q Plot 상으로는 정규분포를 따른다고 볼 수 있지만 정규성 검정 상으로는 p-value가 0.007로 귀무가설을 기각해 정규분포를 따른다고 말할 수 없게 된다.
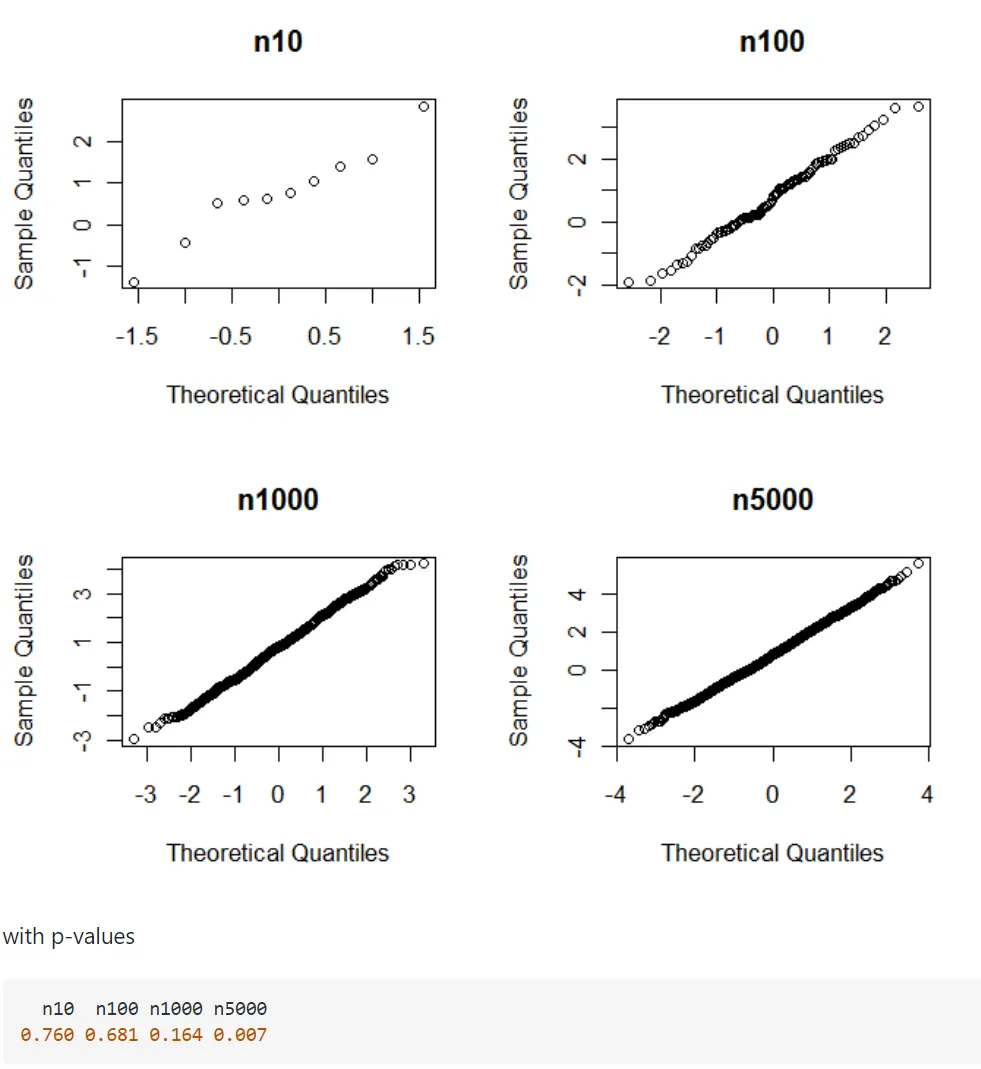
따라서 빅데이터에서의 정규성 검정 결과를 그대로 믿기보다는 이론적 정규성을 판단하기 위한 방법 중의 하나라는 사실 정도만 짚고 넘어가는 편이 바람직하다.