
목차
1. 정의
기댓값 최대화(Expectation Maximization) 알고리즘은 관측되지 않은 잠재변수(latent variable)에 의존하는 확률 모델에서 최대가능도(Maximum Likelihood)나 최대사후확률(Maximum a Posteriori)을 갖는 모수(parameter)의 추정값을 찾는 반복적인 알고리즘이다. (출처: 위키백과)
정의를 보면 어려우니 예시를 들어보자.
예를 들어, 두 확률변수 과 가 iid로 exponential 분포를 따른다고 가정하자.
그런데 이 때 가 관측되었고, 는 관측이 되지 않았다고 하자.(missing) 그럼 이 때 의 추정값을 EM 알고리즘을 통해 구할 수 있다.
2. 프로세스
이제 좀 더 구체적으로 EM 알고리즘의 프로세스를 살펴보자.
가장 먼저 용어를 정리하자. 우선, 우리는 확률변수 X로부터 데이터를 관측하였고 (Observed Data from X), 확률변수 Z로부터는 데이터를 관측하지 못했다고 가정한다. (Missing Data from Z)
그리고 X와 Z를 합친 완전한 데이터를 Y = (X, Z)라고 가정한다. 이 때 모수가 주어졌을 때 y의 likelihood function은 다음과 같이 정리할 수 있다.
이 때 양변에 로그를 취하고 x의 log likelihood function을 왼쪽 변으로 몰아서 정리하면 다음을 따른다.
E-Step
이제 양변에 Expectation을 취해주자. (with respect to the distribution of )
, 라고 하자. 그러면,
M-step
위의 식에서 를 Maximize 하는 것이 우리의 목표라고 했을 때, 우리는 어떤 를 골라야할까?
정답은 를 에 대해 maximize하는 값이다. 그 이유는 는 일 때 최대이기 때문이다.
그러므로 을 를 maximize 하는 값이라고 하면,
이고 이므로,
가 성립한다. 따라서 계속해서 를 update 하면, global maximum에 가까워질 것이다.
3. 예시
몇 가지 예시를 통해 EM 알고리즘을 이해해보자.
Multinomial Distribution
이며 multinomial probability를 가진다고 하자.
그리고 우리는 관측치 를 가지고 있는 상황이다. 이 때 The Complete-data MLE of 를 구해보자.
일단, 과 가 따로 구해지지 않고 더한 값이 관측이 되었기 때문에, incomplete data라고 간주할 수 있다.
이 때 complete-data를 라고 한다면, 는 multinomal distribution을 따르기 때문에 log-likelihood function은 다음과 같다.
이 때 는 sufficient statistics.
1) E-Step
•
•
•
따라서
2)M-Step
이므로 으로 두고 의 MLE를 구하면,
따라서,
3) Code
이를 R과 Rcpp 코드로 구현해보자.
// [[Rcpp::depends(RcppArmadillo)]]
#include <RcppArmadillo.h>
using namespace arma;
using namespace std;
using namespace Rcpp;
// Multinomial Example
//E-Step
NumericVector multi_e(NumericVector x, NumericVector p){
double n1;
double n2;
double n3;
n1 = 38;
n2 = 34;
n3 = 125*(p[2]/(p[3]+p[2]));
NumericVector n = {n1,n2,n3};
return n;
}
//M-Step
NumericVector multi_m(NumericVector n){
double theta = (34+n[2])/(72+n[2]); // 새로운 theta를 구해서
NumericVector p = {1.0/2.0-theta/2, theta/4, theta/4, 1.0/2.0}; // p에 반영
return p;
}
//Update Iteration
// [[Rcpp::export]]
NumericVector multi_out(NumericVector x, NumericVector p, int itr){
for(int i = 0; i<itr; i++){
NumericVector n = multi_e(x, p);
p = multi_m(n);
}
return(p);
}
C++
복사
#RCPP
x = c(38,34,125)
n = rep(0,4)
theta = 1/2
p = c(1/2-theta/2, theta/4, theta/4, 1/2)
itr = 50
multi_out(x,p, itr)
R
복사
[1] 0.1865893 0.1567054 0.1567054 0.5000000
•
50번 Update한 결과
GMM
GMM의 정의
Gaussian Mixture Model(GMM)의 모수를 구하는 데에도 EM 알고리즘이 활용될 수 있다.
Gaussian Mixture Model은 여러 개의 Gaussain 모델이 합쳐진 Clustering 알고리즘이다.
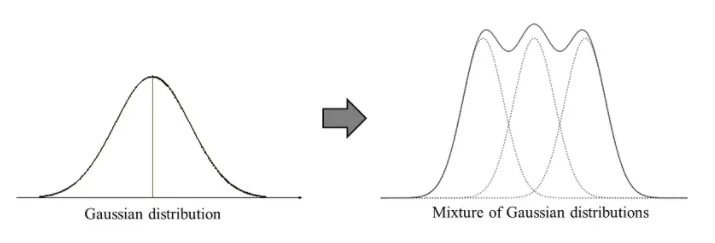
K 개의 Gaussian distribution이 합져져있다고 가정했을 때, Gaussian probability density function은 다음과 같다.
이 때 는 k 번 째 Gaussian distribution이 선택될 확률을 나타내며, 따라서 다음을 만족한다.
결국 우리가 추정하고자 하는 모수는 다음의 세 가지이다.
GMM 모수 추정 프로세스
만약 어떤 값들이 주어졌는데, 이 값들이 K개의 Gaussian distribution이 합쳐진 GMM를 따르는 것은 알겠으나, 모수는 모르는 상황이라고 가정하자.
예를 들어, 다음 그림과 같이 2개의 Gaussian distribution이 합쳐진 GMM에서 온 것으로 추정되어지는 값들이 있다고 하자.

그럼 가장 먼저 2개의 평균값과 분산값을 임의로 설정한다.
예를 들어,
이라고 하자. 설정된 값들을 가지고 그래프를 그려보면,
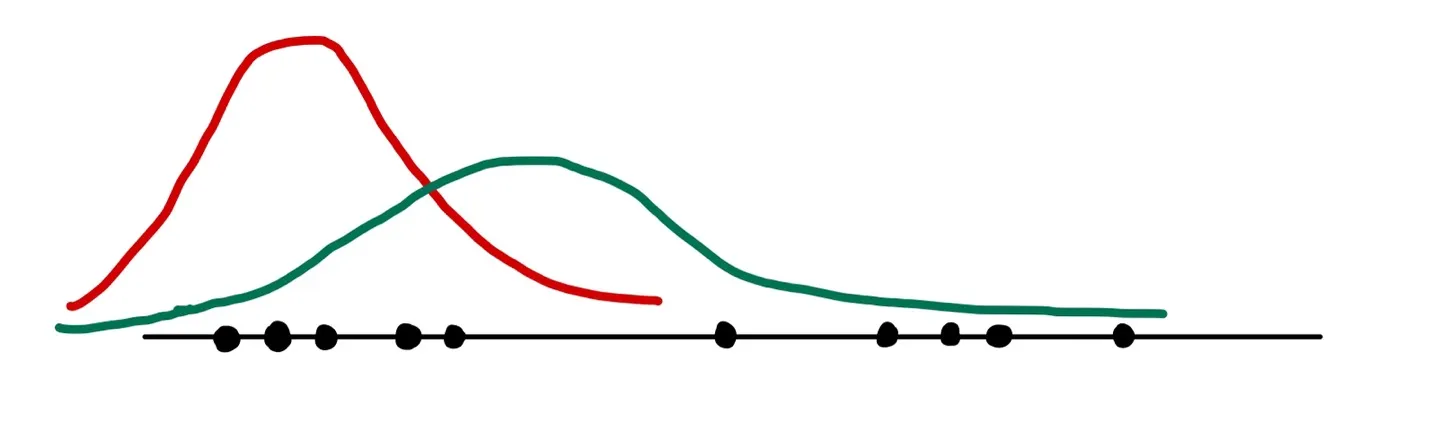
이처럼 나올 수 있다.
그럼 이제 각각의 데이터들에 대하여 확률값(Likelihood)을 구하고, labeling을 수행해줄 수 있다. 예를 들면, 두 번째 데이터에 대하여 과 를 비교하여 더 큰 확률값을 가지는 쪽으로 labeling을 수행하는 것.
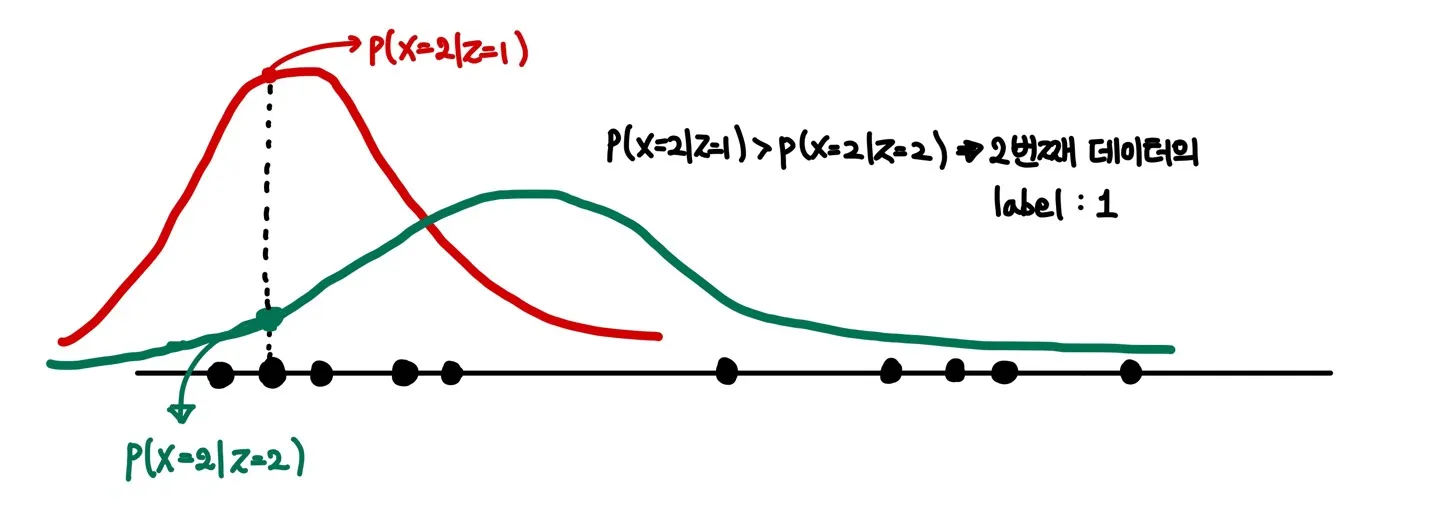
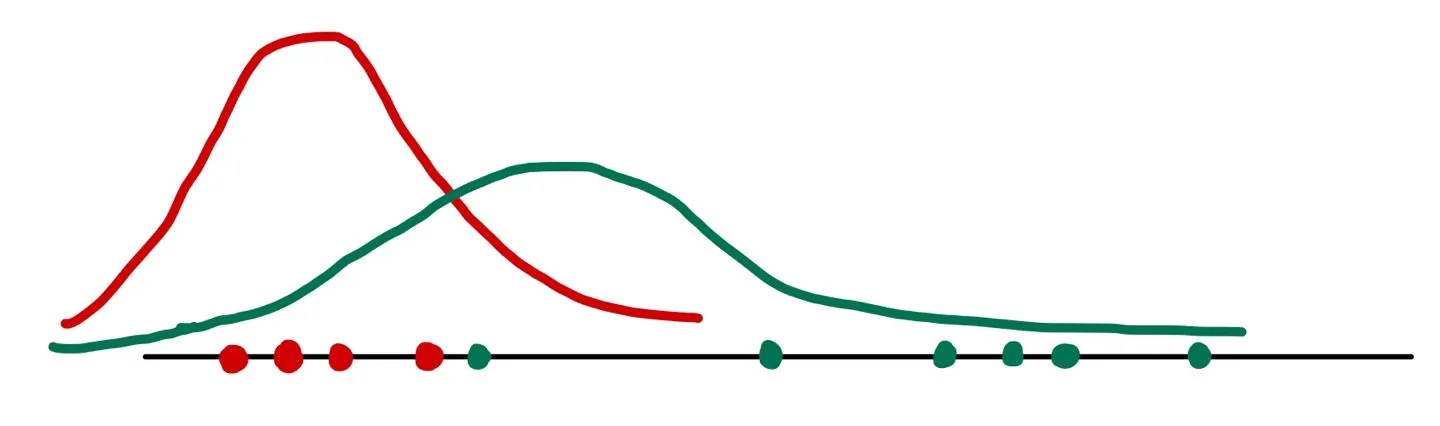
Labeling이 끝난 후에는 labeling된 데이터들을 이용하여 새롭게 모수를 추정한다.

그럼 우리는 새롭게 추정된 모수를 이용하여 다시 labeling을 수행한다. 그리고 이를 반복하면 모수가 수렴할 것이다.
정리하면,
1) K 값 설정
2) 초기 모수값 설정
3) Likelihood 값 기준으로 Labeling
4) 각 그룹별 모수 추정
5) 추정된 모수를 이용하여 분포 제시
6) 수렴할 때까지 3-4 Step 반복
EM 알고리즘 적용
위의 프로세스를 기반으로 EM 알고리즘을 적용해보자.
Z 변수
우선 Latent Variable인 를 설정하자. 잠재변수 는 데이터 x가 특정 cluster에서 왔는가를 나타내는 변수이며
라고 정의한다. 즉, 베르누이 분포(Bernoulli distribution)를 따른다.
따라서 는 시행횟수가 1인 Multinomial Distribution의 형태를 따른다.
그렇다면, 가 주어졌을 때, 확률변수 X의 분포는 다음과 같이 표현할 수 있다.
그러므로, X의 Marginal 분포는 처음에 정의했던 것과 같이 표현될 수 있다.
E-Step
이제 Z 변수를 활용하여 E-Step을 진행하자.
우선 책임값(responsibility)이라는 것을 정의하자. 책임값은 가 주어졌을 때, 일 기댓값을 뜻하며 다음과 같이 표현된다.
그런데 앞에서 는 0 또는 1을 갖는 베르누이 분포를 따른다고 정의했으므로
를 만족한다.
베이즈 정리를 이용하여 책임값을 전개하면,
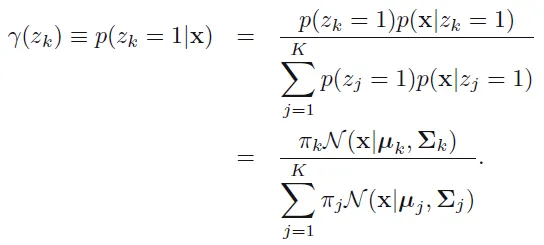
M-Step
앞에서 구한 책임값을 이용하여 M-Step을 진행하자.
우선 확률변수 X의 log-likelihood는 다음과 같다.
이제 각각의 모수에 대하여 MLE를 구하기 위해 log-likelihood의 편미분 값이 0이 되는 지점을 찾자.
1)
2)
3) (mixing coefficient)
mixing coefficient는 앞에서 언급했듯이 0에서 1사이라는 제약조건이 있다. 따라서 라그랑주승수를 이용하자.
정리
EM 알고리즘 Step을 다시 정리하면,
1) 등의 모수들을 모두 초기화 하고 랜덤 값을 부여한다.
2) E-Step: 파라미터들을 고정하고 responsiblity(책임값)을 구한다.
3) M-Step: 2)에서 구한 responsibility로 모수들을 update 한다.
4) log-likelihood로 평가한다.
5) 2-4 Step을 반복한다.