프로젝트 주제
여러 데이터를 활용하여 오산시 내 각 지역들의 어린이 교통사고 위험도 지수를 산출하고 이를 바탕으로 어린이 교통사고 위험지역을 도출하였다.
데이터
•
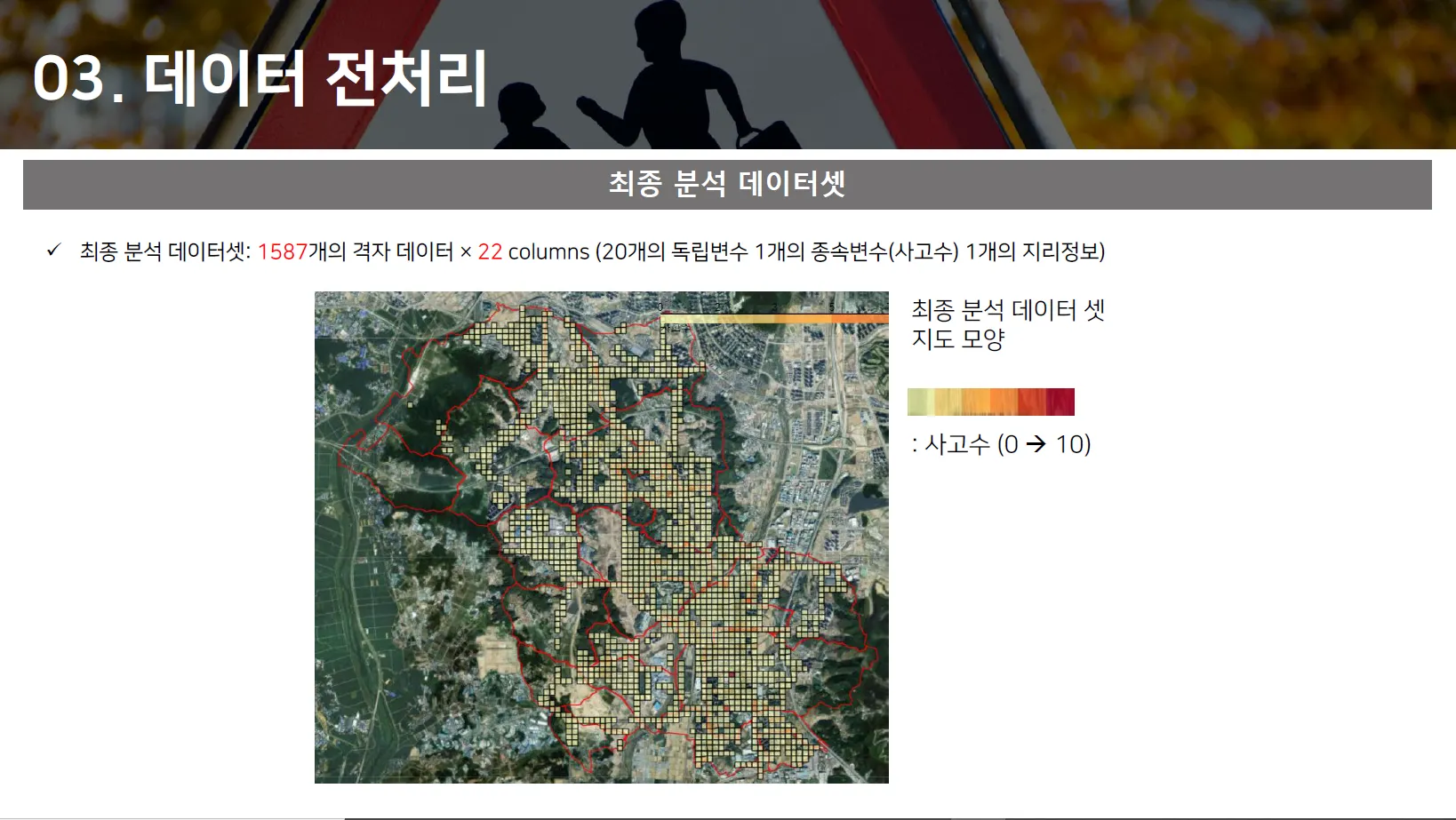
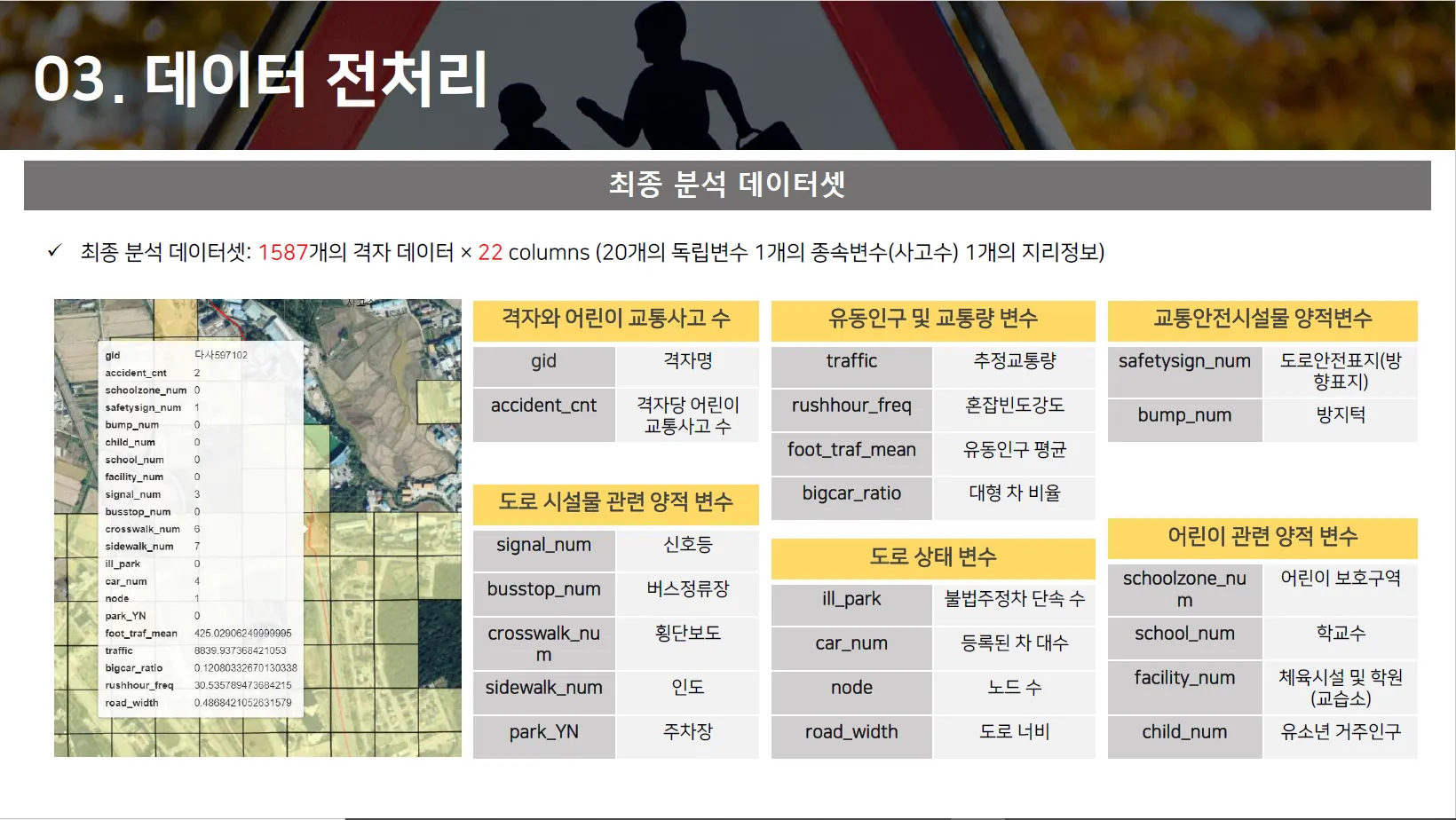
Processing 이후 최종 격자 수: 1587개
•
Target Variable: 격자 내 어린이 교통사고 수.
•
Predictor Variable: 오산시 차량등록현황 등 오산시 관련 데이터. → Processing 후 20개 사용.
모델 및 성능
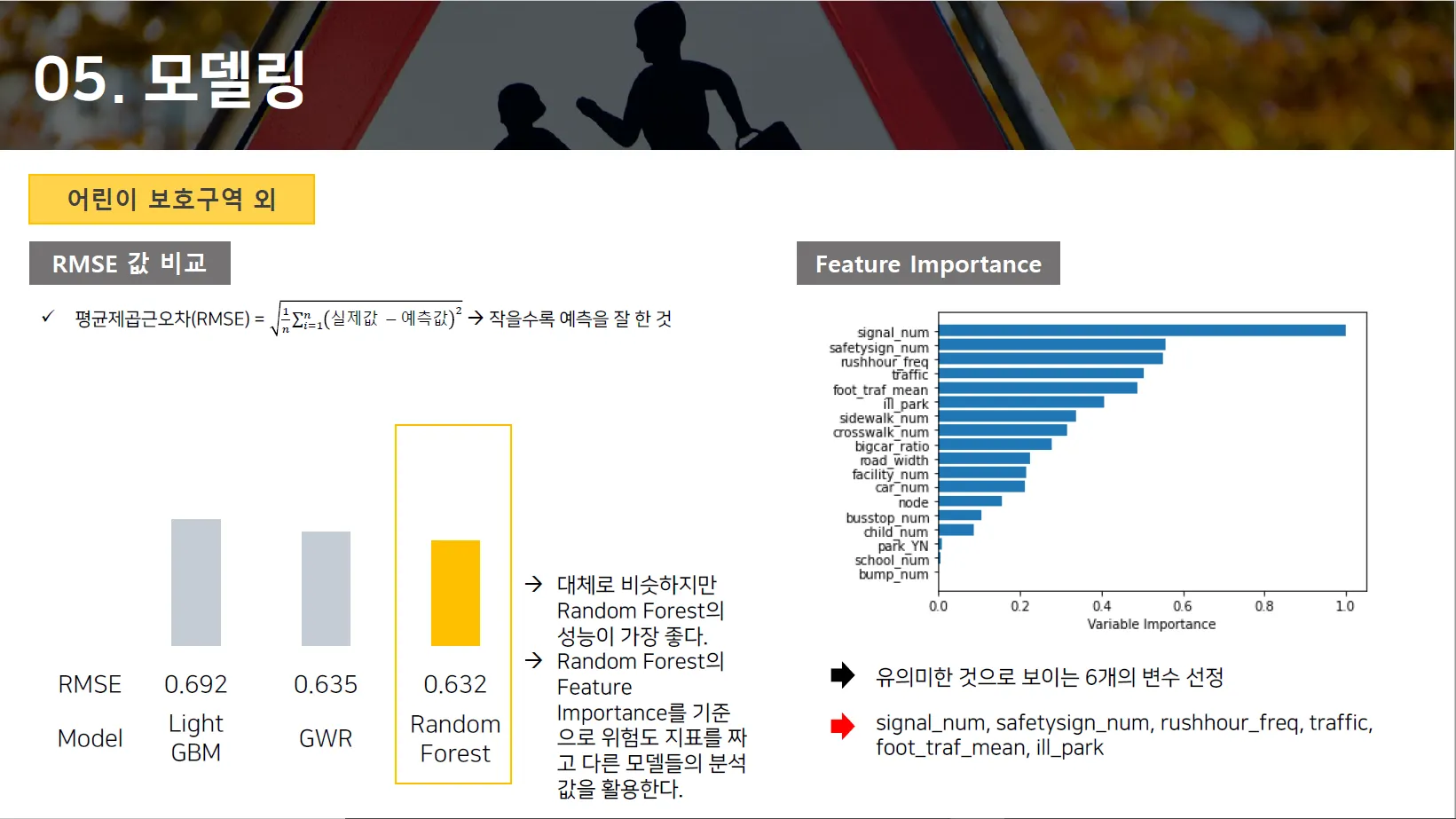
Random Forest와 GWR(Geographically Weighted Regression)을 결합하여 교통사고 위험도 지수를 생성하였다.
Random Forest의 RMSE는
•
어린이 보호구역 외: 0.632
•
어린이 보호구역 내: 0.730
으로 나타났다.
GWR은 위험도 지수를 생성할 때 변수의 부호를 판별하기 위하여 사용하였음.
결론
의의
•
결과적 유의성: 어린이 보호구역과 어린이 보호구역 외의 위험도 지수가 높은 지역을 살펴본 결과 일반적으로 생각하는 교통사고 위험 요인(추정 교통량, 유동인구)들 또한 높은 것을 확인할 수 있었고 배경지식에서 예상했던 바와 같이 중앙동과 대원동 근처에 위험지역이 많은 것을 확인할 수 있었다.
•
독창성: 통계 모델을 사용하여 오산시 만의 특성을 반영할 수 있는 위험도 지수를 산출하였다.
•
시각적 활용: 지도를 제작하였기 때문에 한눈에 위험 지역을 파악할 수 있었다. 또한 검색 기능을 이용하여 해당 격자를 찾을 수 있도록 하였다.
•
경제성 및 공공성: 모든 자료는 기본 제공 자료와 공공자료, 오픈 소스들을 활용하였으며, 데이터 추가를 제외하면 모델을 발전시키는 데에 비용이 들지 않았다.
•
추후 발전 가능성: 추후 데이터를 추가하여 모델에 반영하면 더 정확한 위험도 지수를 산출할 수 있다.
한계
•
데이터의 부족 및 불완전성: 필요한 곳의 데이터가 없거나 불완전한 경우들이 있었다. 예를 들어 도로가 있음에도 도로 정보가 없는 지역이 존재하였다.
•
적은 어린이 보호구역 수: 어린이 보호구역의 경우 원래 숫자가 적기 때문에 어린이 보호구역 외에 비해 비교적 분석의 정확도가 떨어졌다.
제언 및 활용방안 제시
•
데이터 보완: 정기적으로 데이터를 갱신 또는 추가하는 경우 더욱 정확한 분석 결과를 얻을 수 있을 것.
•
오산 시 외의 데이터와 결합하여 분석: 오산시와 비슷한 특징을 가진 도시와의 데이터와 결합하여 분석을 진행한다면 충분한 수의 어린이 보호구역 데이터 수를 얻을 수 있을 것.
•
활용방안: 위험지역으로 표시된 곳에 안전시설물이 부족한 경우 안전시설물 설치 우선지역으로 선정할 수 있으며, 이를 통해 어린이 교통사고를 방지할 수 있을 것으로 기대.
Table
Search
Github