
1. 정의
순열검정법(permuation test)은 두 개 이상의 표본을 함께 결합하여 관측값들을 무작위로 재표본으로 추출하고 이를 이용하여 가설 검정을 진행하는 방법을 말한다. 이때 재표본 추출(resampling)은 비복원 방식으로 진행한다.
2. 절차
좀 더 자세하게 살펴보자. 일단 두 그룹의 샘플 데이터가 주어졌다고 가정하자(이해를 돕기 위해 두 그룹으로 가정).
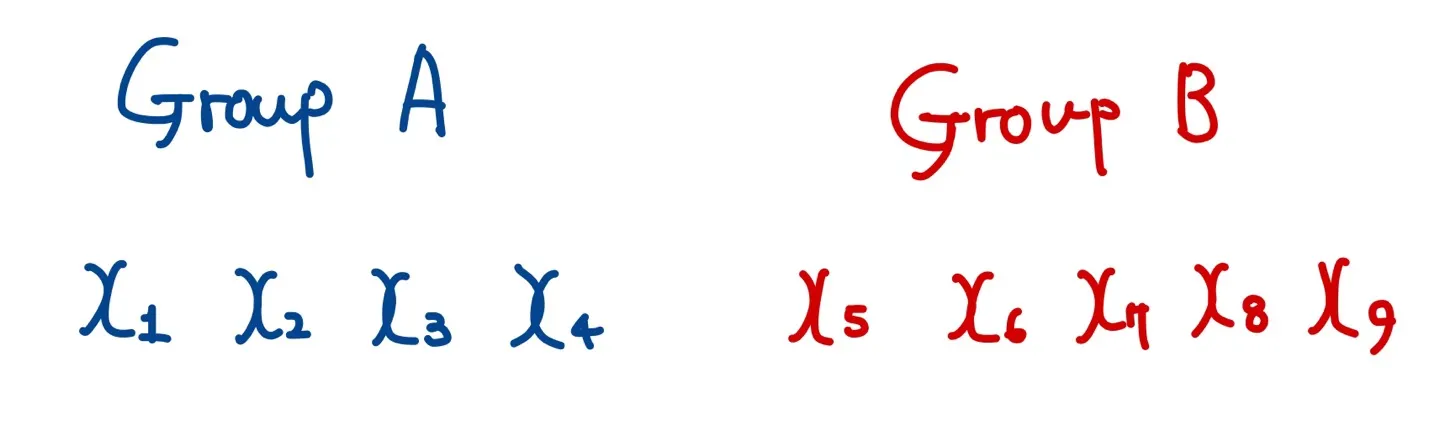
그리고 두 그룹의 샘플 데이터를 이용하여 검정 통계량을 구한다. (예를 들어 평균의 차이 등) 이때 검정 통계량을 observed test statistics라고 부른다.
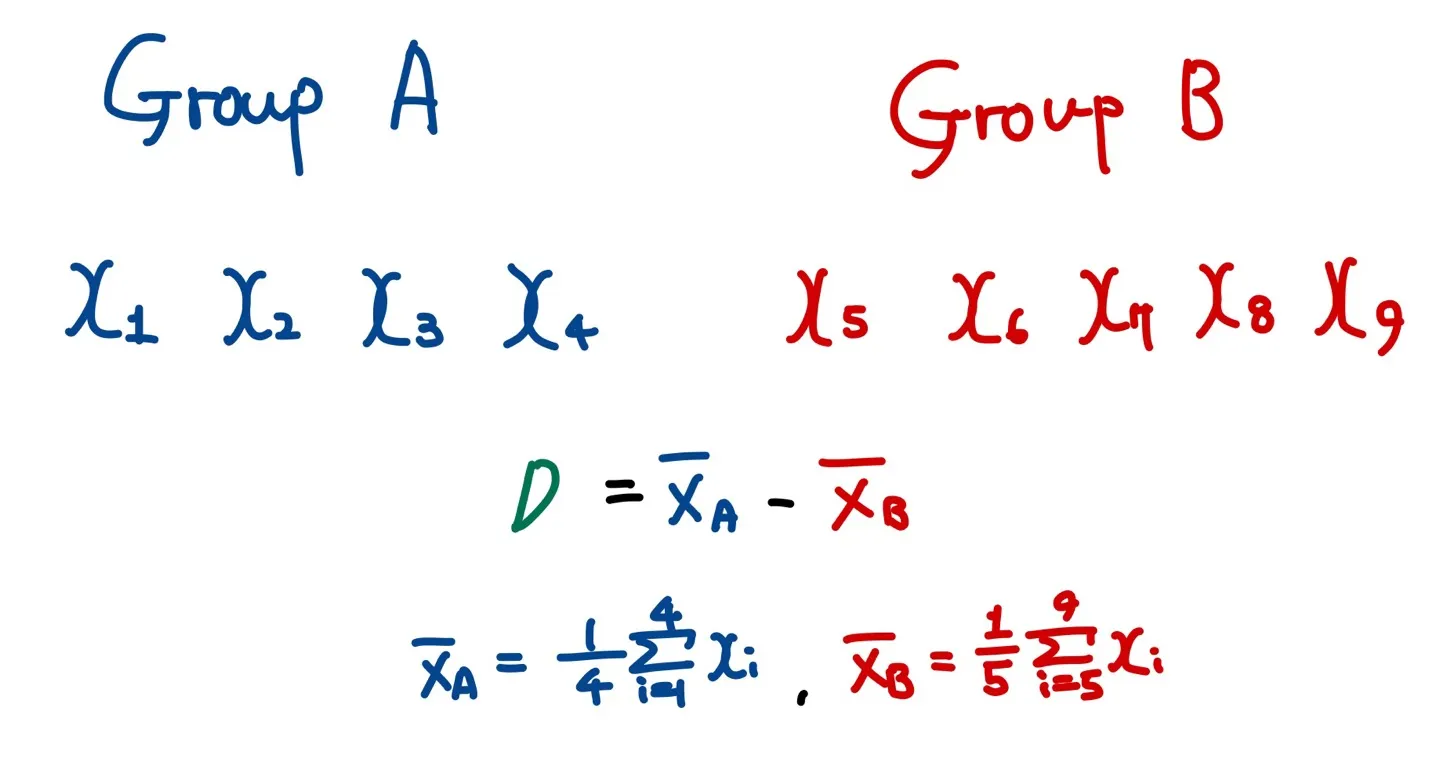
이제 이 검정 통계량이 유의미한지 검정해보자. 우선, 두 그룹의 데이터셋을 하나의 데이터셋으로 묶은뒤, 비복원 추출을 통해서 다시 그룹 A와 그룹 B로 나눈다. 이때 각각의 그룹의 데이터 개수는 기존의 그룹의 데이터 개수와 동일해야 하며 각 데이터 포인터들이 뽑힐 확률은 이다. (비복원 추출이란 중복을 허용하지 않고 샘플링 하는 것을 의미한다.)
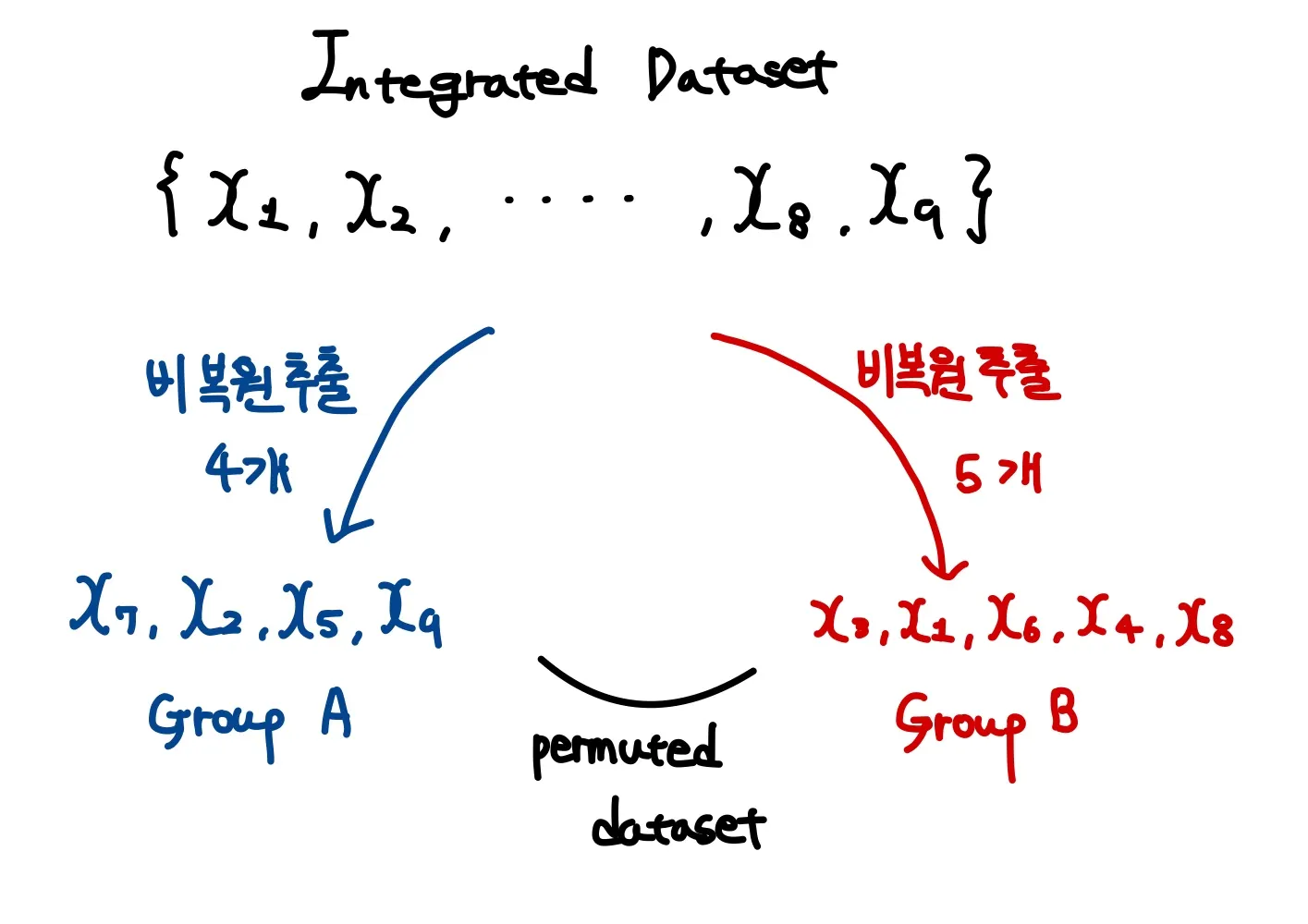
리샘플링된 데이터셋을 permuted dataset이라고 부르는데, 이 permuted dataset을 이용하여 다시 동일한 방식으로 검정 통계량을 구한다. 이때의 검정 통계량을 permuted test statistics라고 부른다.
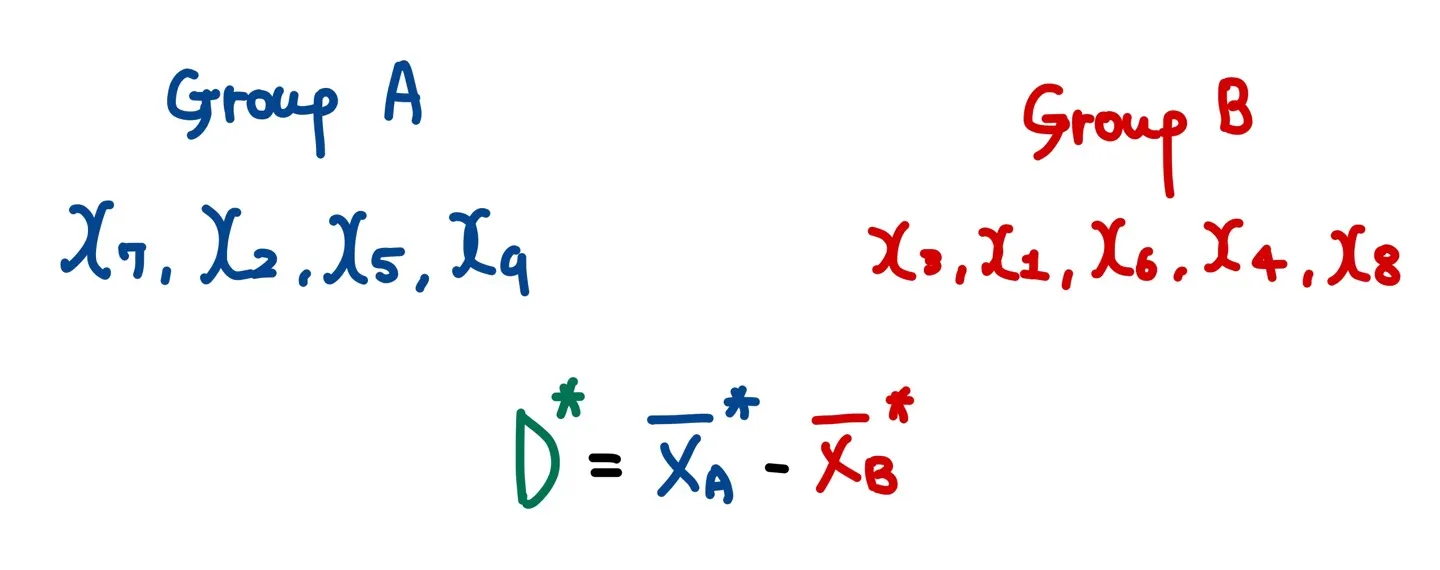
이를 총 m번(충분히) 반복하고 empirical p-value를 구한다.
단측 검정인 경우, permuted test statistics가 observed test statistics보다 클 확률 또는 작을 확률을 구하고 양측 검정인 경우에는 permuted test statistics의 절댓값이 observed test statistics보다 클 확률을 구한다.
예를 들어, 전체 리샘플링 횟수 1000번에서 20개의 검정 통계량이 observed test statistics인 D보다 큰 값이 나왔다고 하자. 그럼 단측 검정이라고 했을때 empirical p-value의 값은
이다. 즉, D는 permuation 분포 상에서 상당히 높은 위치에 속한다는 것이다.
이제 empirical p-value를 significance level(유의 수준)과 비교하여 significance level보다 낮으면 통계적으로 유의하다고 간주한다. 만약 위의 예시에서 0.05를 유의 수준으로 잡으면 p-value가 더 작기 때문에 표본 평균의 차이가 통계적으로 유의미하다고 간주한다.
절차를 다시 정리하면 다음과 같다.
1.
기존의 데이터셋에서 검정 통계량(observed test statistics)을 구한다.
2.
각 그룹의 데이터들을 섞은 뒤, 비복원 추출을 통해 permuted dataset을 구한다.
3.
permuted dataset을 이용하여 permuted test statistics를 구한다.
4.
2-3 step을 m번 반복한다.
5.
m개의 permuted test statistics를 이용하여 permutation 분포를 구한다.
6.
emprical p-value를 구하고 significance level과 비교하여 가설을 검정한다.